阿里国际数字商业集团 Lazada 首页 & 内容团队,正在热聘 Java、C++ 服务端 P6 岗位,Base 广州,欢迎自荐或推荐
我们正在寻找对技术充满热情的你,共同打造电商领域的智能化未来!无论你是专注于高性能推荐引擎的架构设计与优化,还是热衷于大模型 Agent 的落地应用与推理性能提升,抑或是探索生成式推荐与导购助手的创新场景,这里都有广阔的舞台。我们期待具备扎实计算机基础、熟悉算法与数据结构、热爱解决复杂问题的你加入,一起用技术创新驱动业务变革,定义行业新高度!

阿里国际数字商业集团 Lazada 首页 & 内容团队,正在热聘 Java、C++ 服务端 P6 岗位,Base 广州,欢迎自荐或推荐
我们正在寻找对技术充满热情的你,共同打造电商领域的智能化未来!无论你是专注于高性能推荐引擎的架构设计与优化,还是热衷于大模型 Agent 的落地应用与推理性能提升,抑或是探索生成式推荐与导购助手的创新场景,这里都有广阔的舞台。我们期待具备扎实计算机基础、熟悉算法与数据结构、热爱解决复杂问题的你加入,一起用技术创新驱动业务变革,定义行业新高度!
作为 Kotlin 服务端开发者,你可能已经厌倦使用 MyBatis 和 Hibernate,希望寻找一款专为 Kotlin 开发的 ORM 框架。而 Ktorm 就是一款专门为 Kotlin 设计,旨在让数据库操作更加流畅、自然,更贴合 Kotlin 语法特性的 ORM 框架。
在这场分享里,将跟大家介绍 Ktorm 的核心设计、框架使用和扩展,并通过使用 Ktorm 写出更具 Kotlin 风味的数据库操作代码。听完这场分享后,将会对如何善用 Kotlin 语法来设计 ORM 框架有进一步的认识。
PPT 下载链接:ktorm-in-kotlin-conf-cn-2024.pdf
Gravatar 即全球通用头像 (Globally Recognized Avatar) 服务,用户只要在上面上传了自己的头像,那么在所有支持的网站上发帖时,只要提供与这个头像关联的 Email,就可以显示出自己的 Gravatar 头像。可以说是「一次上传,全网通用」~~
可惜国内的网络环境实在一言难尽,Gravatar 常年都处于无法访问的状态,所以本站一直都是用 v2ex 提供的 CDN 镜像,然而,就在前两周,v2ex 也被墙了,emm… 因为不想再白嫖其他的国内镜像,因此开始考虑自己动手搭建。这个事情其实挺简单的,网上随便搜索一下就有答案,只要有一台墙外的 VPS,用 nginx 给 Gravatar 做个反向代理就好。
但是,如果你的主机在墙内呢,怎么办?
无论如何,科学上网是第一件必须解决的事情。如果你的主机甚至都不能访问 Gravatar,反向代理根本就无从谈起。要实现科学上网,你首先需要在墙外有可用的 Shadowsocks 服务用于代理你的流量,至于是使用 VPS 自建也好、直接购买机场的服务也好,这里不作探讨。
安装 Shadowsocks:
1 | apt-get install python-pip |
在 /etc/shadowsocks/config.json 目录创建一个配置文件:
1 | { |
配置完成后,使用 sslocal 命令启动客户端服务:
1 | sslocal -c /etc/shadowsocks/config.json -d start |
这个命令会在本地 1080 端口启动一个 socks5 代理,连接远程的 Shadowsocks 服务,把网络请求转发过去。
接下来检查一下这个代理是否可用,使用 curl 命令查询一下自己的 IP,--socks5-hostname 参数指定 socks5 代理服务的地址:
1 | $ curl --socks5-hostname 127.0.0.1:1080 cip.cc |
可以看到,IP 地址是国外的,证明我们已经可以科学上网了。
照理说,实现科学上网之后,直接在 nginx 配置反向代理就能完成我们的任务。但遗憾的是,nginx 本身并不支持使用系统代理,也不像 curl 那样提供了 --socks5-hostname 参数用于显式指定代理,因此我们只能另谋出路。
这时我想到了 socat,socat 是一个多功能网络工具,它可以在两个网络数据流之间建立通道,实现端口转发的功能,同时还支持代理。但可惜的是,socat 目前只支持 socks4,还不支持 socks5,所以还不能直接用。在 GitHub 搜索发现已经有大佬给 socat 打过补丁,使其支持 socks5,因此决定使用这个补丁版本试试。这里给出项目的地址,有兴趣可以去点个 star:https://github.com/runsisi/socat
要安装这个补丁版的 socat,我们就不能直接使用 yum 或者 apt-get,而是要下载源码自己编译:
1 | apt-get install git curl autoconf yodl make |
注意,上面的第一步首先安装了编译的过程中需要用到的其他工具,其中 yodl 在 CentOs 中可能无法使用 yum 安装,也可以考虑通过下载源码自行编译的方式解决,项目地址:https://gitlab.com/fbb-git/yodl
安装之后,启动 socat,监听 1081 端口,把流量转发给 Gravatar,当然,需要走代理:
1 | socat -d -d TCP4-LISTEN:1081,reuseaddr,fork SOCKS5:127.0.0.1:www.gravatar.com:443,socks5port=1080 |
尝试访问一下 1081 端口,发现已经可以正常获取到头像数据了:
1 | $ curl -v -k -H 'Host: www.gravatar.com' -o /dev/null https://127.0.0.1:1081/avatar/123 |
有了前面的准备工作之后,我们终于可以在 nginx 配置反向代理了,不过这里要注意的是,不能直接把流量转发给 Gravatar,而是转发给刚刚使用 socat 开启的本地 1081 端口。同时,为了减少回源的次数,提高访问速度,我们还可以做一层 proxy_cache 缓存。具体配置如下:
1 | http { |
配置完成后,尝试使用浏览器打开一个头像链接,确认是否能正常访问:https://www.liuwj.me/gravatar/123
大功告成!!一个头像请求,从浏览器发出之后,经过的路径应该是这样子的:
1 | +---------+ +-------+ +-------+ +---------+ +----------+ +----------+ |
可以说是十分曲折了…
]]>本文转自 https://skyblond.info/archives/751.html
最近从滴滴辞职,为期 5 天的暑假正式开始了,寻思着做一点有意义的事情提升一下自己。遂决定自己写一套专门用于复杂查询的通联日志管理系统,数据库选用了 PostgreSQL,该数据库可以直接对 Json 类型的数据进行高级查询,然而 Ktorm 框架并不支持此功能,因此本文将记述为该框架进行拓展的过程。
假设数据库中有一表 qso_infos 用于存储通联日志,其中 qsl_info 字段表示 QSL 相关事宜的记录,该字段为 jsonb 类型,样例如下:
1 | { |
现在需要查询所有 LoTW 未上传的记录,应当如何利用 Ktorm 在数据库端完成?
如果需要查询所有 comment 为空的记录,应当如何利用 Ktorm 在数据库端完成?
如果直接编写 SQL 的话,应当按如下编写:
1 | SELECT * FROM qso_infos WHERE qsl_info->'lotw'->>'uploaded' = 'false'; |
其中第一句还可以这样写:
1 | SELECT * FROM qso_infos WHERE (qsl_info->>'lotw')::json->>'uploaded' = 'false'; |
第一种写法用到了两个不同的运算符:-> 是作为 Json 取出,而 ->> 则是作为字符串取出。需要注意的是对于 Json Object 这两个运算符是根据输入的字符串作为键去取值,而对于 Json Array 则是按照输入的整形作为从 0 开始的索引去取值。为了最大兼容性的考虑,本文将同时实现每个运算符的两个形式。
对于第二种写法,虽然只需要自定义一个运算符即可,但还需要将转换为 Json 作为一个额外的运算符实现。本文也将实现该运算符。
为了实现对 Json 的访问,首先应当定义 json 和 jsonb 两个 SQL 数据类型。这里我没有使用 ktorm 的模块,而是基于 Gson 写了一个:
1 | package info.skyblond.jinn.extension |
关于代码就不多说了,具体可以参考 Ktorm 文档 - 定义表结构 - 扩展更多的类型。这里最重要的一点就是要使用限制比较宽松的框架进行 Json 转换,一开始我试图使用 kotlinx 的 serialization 进行,于是进行 Json 转换的时候就需要一个 KSerializer 对象才能工作,而该对象的获取渠道是 SomeClass.serializer(),其中 SomeClass 需要被 @kotlinx.serialization.Serializable 注解。之后进行 Json 操作时为了最大的兼容性,通常都是认为操作的结果是 Any 而非特定一个类,那么问题就来了:Any 类似 Java 的 Object,是万物之父,而所有被 @Serializable 注解的类,可没有一个统一的父类。因此这样的架构在后续实现运算符的时候就会非常难受。最起码也是要实现了 Java 的 Serializable 接口(或其他框架的统一的接口)。
现在有了 Json 数据类型,接下来我们就可以实现运算符了。
关于自定义运算符,这里同样不多赘述,详细指导可以参考 Ktorm 文档 - 运算符 - 自定义运算符。拓展的代码如下:
1 | package info.skyblond.jinn.extension |
在这里我们实现了 AsJsonExpression,该表达式将前面的语句转换成 Json 类型;JsonAccessExpression,该表达式将对 Json 类型的数据进行 -> 运算;JsonAccessAsTextExpression,该表达式将对 Json 类型的数据进行 ->> 运算。
在 Ktorm 中对于数据的面向对象式筛选,实际上是基于面向对象的写法产生一个表达式树。该树中的每一个 Expression 表示一个运算或参数,最终将被解析为一条 SQL 语句。
值得注意的是在 AsJsonExpression 的实现中只有 left,原本是打算将其作为 AsDataTypeExpression,然后 right 作为一个 SqlType 来实现更通用的功能的,但是这样一来后面的实现将无法保证只对 Json 类型的语句进行访问:JsonSqlType 要能够适配所有情况,其类型必定是 SqlType,这样一来将无法区分哪些表达式是 Json,哪些不是。当然你也可以额外在加一个类型:AsDataTypeExpression,T 作为 SqlType,而 U 直接存储 JsonSqlType,但是就本文而言,还是单独搞一个 AsJsonExpression 来的最实在。
关于 asJson() 函数,设置 alreadyJson 的目的就是后面对于 -> 运算符,其运算结果本身就是 Json,而对于编译器来说则是 JsonAccessExpression 类型,不能应用 AsJsonExpression 的访问操作。因此这里只是单纯的为了让编译器开心,当进行 -> 访问时,除了产生一个访问表达式之外,还在外面报一个 AsJsonExpression,这样对于编译器来说就是合法的 Json 类型了,而在生成 SQL 语句时通过判断 alreadyJson 字段可以跳过本次类型转换。
最后为了写起来更舒爽,对于作为 Json Object 取出的 -> 运算,我重载了 kotlin 内置的 get 方法,这样就可以通过 asJson()[keyName] 的形式进行访问了。
而只进行到此还是不够全面,目前 ktorm 还不能正确翻译这些表达式。下一步将进行方言扩展。
既然说扩展方言,就是说我们并不像替代原有的 PostgreSQL 方言,而 Ktorm 的作者也贴心的将方言实现类加了 open 关键字,这样我们就可以自由的进行扩展了。根据 Ktorm 文档 - 运算符 - 自定义运算符,扩展的方言应当覆盖对未知表达式的处理:
1 | package info.skyblond.jinn.extension |
在遇到没有见过的表达式时,将回调父类的处理函数,而这个函数的默认行为就是抛异常。这里在产生 SQL 语句的时候有一些细节要注意。
对于转换为 Json 的语句,需要时应当增加括号来保证运算优先级的正确性。而对于 Json 的访问,其左值一定是 Json,而右值则一定是数字或字符串类型的参数,因此左右皆无需增加括号。
最后我们需要在连接数据库的时候指定该方言。
首先连接数据库:
1 | val pgDataSource = PGDataSource() |
注意最后在连接数据库的时候指定了我们自己实现的方言。之后在定义完表和实体类之后进行查询:
1 | database.sequenceOf(QsoInfos).filter { |
对应的分别产生了如下 SQL:
1 | DEBUG org.ktorm.database - SQL: select ... from qso_infos where ((qso_infos.qsl_info -> ?) ->> ?) = ? |
看起来符合预期,程序也没有报错。至此可以算是完美决绝问题。
- 全文完 -
]]>Banner。但是当我打开这个类的时候,看到的除了字段定义以外还有一大堆使用 idea 生成的 getter/setter 方法。甚至这些 getter/setter 方法占用的代码行数反而更多,严重干扰视线,阅读代码体验极差。
这时我就产生了重构的想法,思路是删掉这些没必要的 getter/setter 方法,改用 lombok 的 @Data 注解代替。因为 lombok 本来在项目中就有使用,所以应该不会有什么问题。改完之后,我测试了我正在做的这个功能,一切正常,代码部署到测试环境之后也运行良好。
但是万万没有想到,问题竟然出现在与这个功能看起来毫不相关的另一个模块。这个模块启动后抛出了一个 NoSuchMethodError:
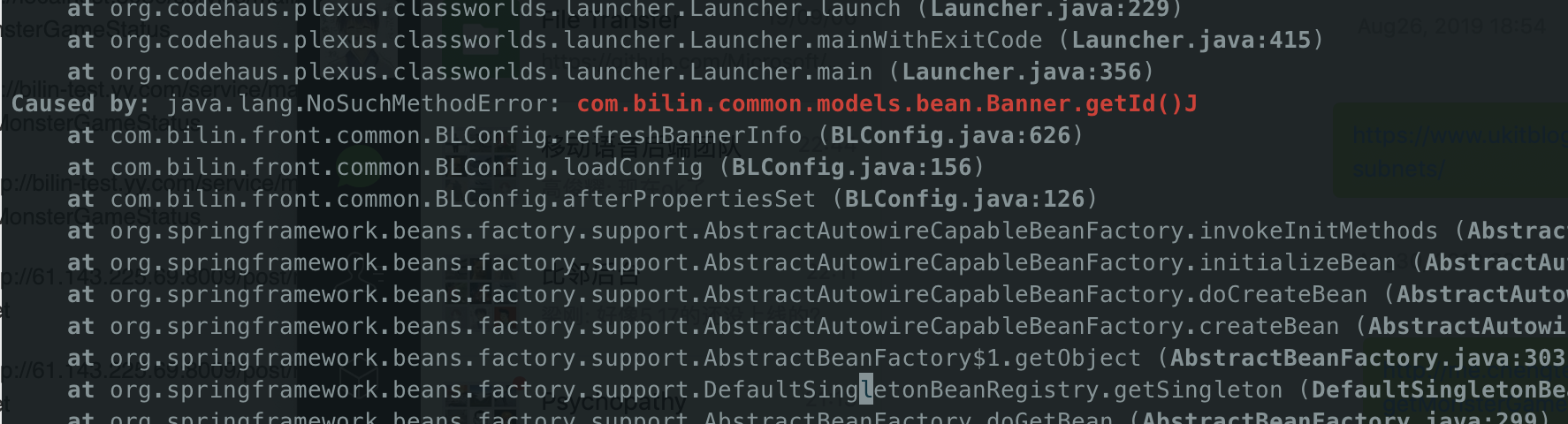
抛异常的地方确实是我改过的 Banner 类,但是 lombok 应该会为我们生成相应的 getter/setter 方法,所以这里不应该找不到才对,难道是 lombok 抽风了?
查找原因的时候,有的同事认为原因是我把 lombok 的依赖设置成 optional,导致运行的时候没有 lombok 的 jar 才出现这个异常。然而这种理解是错误的,因为 lombok 生成代码的原理是通过 javac 提供的 APT(Annotation Processing Tool,注解处理器)机制在编译过程中对 Java 代码的 AST 进行修改,这一切都发生在编译时,因此在运行时并不需要 lombok 的存在。换句话说,如果是因为 lombok 导致的问题,不会等到运行的时候才抛出异常,而是在编译的时候就崩了。
真正的原因比较隐蔽,仔细寻找之后才能发现。在我修改前的 Banner 类中,有一个 id 字段,它的定义是这样的:
1 | private Long id; |
可以看到,这里使用的是包装类型的 Long,但是它的 getter/setter 方法使用的却是基本类型的 long:
1 | public long getId() { |
严格来说,这样根本不符合 Java Bean 的规范,使用 idea 也不可能会生成这样的 getter/setter 方法,所以我猜测原代码的作者应该是先使用 idea 生成了代码,然后手动修改了里面的类型。
当我把这两个方法删掉,加上 lombok 的 @Data 注解之后,lombok 给我们生成的的 getter/setter 方法的类型会与字段的类型相同,即 Long getId()。
理论上,当方法的签名从 long getId() 变成 Long getId() 之后,代码是不会报错的,因为就算原来有地方使用了 long 来接收返回值,我们的方法签名改成 Long 之后返回的包装类型也会被自动拆箱。然而正因为它不会报错,才让我没有立即发现问题。
当我们讨论一段被修改的代码的兼容性的时候,我们其实隐含了两层完全不一样的意思。兼容性分为两个层次:
一般来说,我们平时写代码只需要做到源码级兼容即可,二进制级兼容只在很少情况下才会需要。
在这个例子中,我们的方法签名在无意间从 long getId() 变成了 Long getId(),这在源码层面是兼容的,所以编译的时候不会报错。但是在 Java 字节码中,long getId() 和 Long getId() 是两个完全不一样的方法,因此这个修改是二进制不兼容的。
我的项目的模块依赖是这样的:
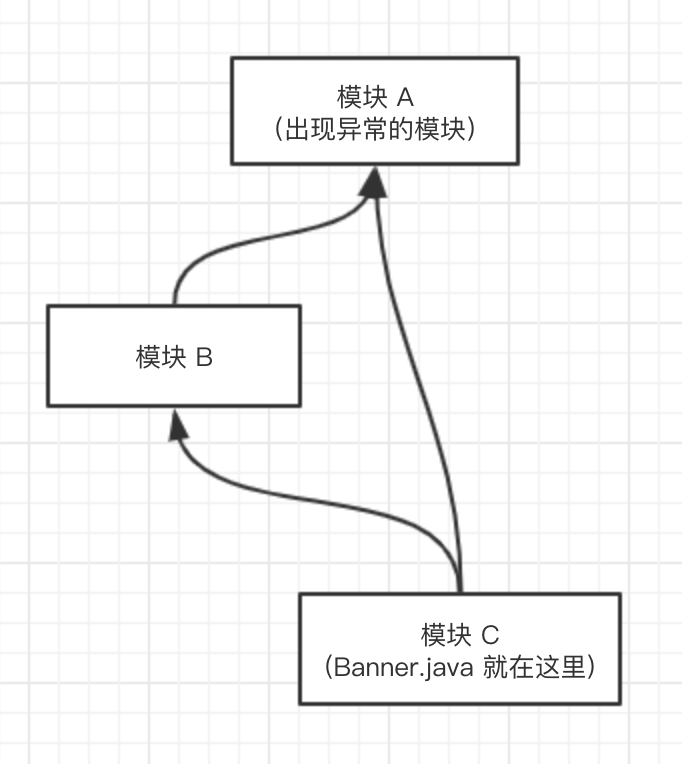
Banner.java 在模块 C 中,我修改之后 deploy 了一个新版本到 maven 仓库,因此其他模块可以下载到它。
模块 B 依赖了模块 C,并且在里面使用了 Banner 类的 long getId() 方法,这正是发生这次错误的原因。
模块 A 同时依赖了模块 B 和模块 C。因为我修改过模块 C,并且 deploy 了一个新版本,因此在构建的时候会下载这个最新的 jar 包,但是我并没有修改过模块 B,所以模块 A 在构建的时候使用的仍然是旧的 jar 包。这个旧的 jar 包在运行的时候会尝试去调用签名为 long getId() 的方法,但是这个方法的签名已经被我在无意间改成了 Long getId(),因此才会发生找不到方法的异常。
找到异常的原因之后,解决方法很自然就有了,那就是重新编译模块 B,并把它 deploy 到 maven 仓库中即可。
这次的问题是一个说明代码兼容性的不同层次的一个很好的例子,这种问题排查起来虽然不算太难,但是发生的原因十分隐蔽,也足够我们折腾一会。为了避免大家以后踩到和我类似的坑,在这里我把整个过程记录下来,然后给出一点不成熟的小建议:
当然,最好的方法还是赶紧换成 Kotlin (强行安利),去 tm 的 getter/setter…
]]>前文地址:你还在用 MyBatis 吗,Ktorm 了解一下?
Ktorm 官网:https://www.ktorm.org
在开始之前,我们先回顾一下上篇文章中的员工-部门表的例子,这次我们的示例也是基于这两个表。下面是使用 Ktorm 定义的这两个表的结构:
1 | object Departments : Table<Nothing>("t_department") { |
在上面的表定义中,我们可以看到,Ktorm 一般使用 Kotlin 中的 object 关键字定义一个继承 Table 类的对象来描述表结构。这里的 Departments 和 Employees 都继承了 Table,并且在构造函数中指定了表名。表中的列使用 val 关键字定义为表对象中的成员属性,列的类型通过 int、long、varchar、date 等函数定义,它们分别对应了 SQL 中的相应类型。
在 Ktorm 中,int、long、varchar、date 这类函数称为列定义函数,它们的功能是在当前表中增加一条指定名称和类型的列。Ktorm 内置了许多列定义函数,它们基本涵盖了关系数据库所支持的大部分数据类型。但是,在某些情况下,我们需要在数据库中保存一些原生 JDBC 所不支持的特殊类型的数据(比如 json),这就要求框架能给我们提供扩展数据类型的方式。
SqlType 是 Ktorm 中的一个抽象类,它为 SQL 中的数据类型提供了统一的抽象,要扩展自己的数据类型,我们首先需要提供一个自己的 SqlType 实现类。下面的 JsonSqlType 使用 Jackson 框架进行 json 与对象之间的转换,提供了 json 数据类型的支持:
1 | class JsonSqlType<T : Any>( |
有了 JsonSqlType 之后,接下来的问题就是如何在表对象中添加一条 json 类型的列。我们已经知道,int、varchar 等内置列定义函数的功能正是在当前表对象中注册一条相应类型的列,那么我们能不能自己写一个列定义函数呢?
如果我们用的是 Java,这时恐怕只能遗憾地放弃了,但是 Kotlin 不一样,它支持扩展函数!Kotlin 的扩展函数可以让我们方便地扩展一个已经存在的类,为它添加额外的函数。
1 | inline fun <reified C : Any> BaseTable<*>.json( |
使用上面这个扩展函数,我们可以很方便地在当前表对象中添加一条 json 类型的列,它的用法和 Ktorm 内置的列定义函数没有任何区别。
1 | object Employees : Table<Nothing>("t_employee") { |
扩展函数是 Kotlin 的一项重要特性,可以让我们在不修改一个类的情况下,为它添加额外的属性和函数,这极大地提高了我们编程的灵活性。Ktorm 对扩展函数有许多的应用,它的绝大部分 API 都是通过扩展函数的方式来提供的。实际上,前面提到的 int、varchar 等内置列定义函数也都是通过扩展函数实现的。
DSL(Domain Specific Language,领域特定语言)是专为解决某一特定问题而设计的语言。与通用编程语言相比,DSL 更趋向于声明式,能够更加简洁地表达特定领域的操作。Kotlin 为我们提供了构建内部 DSL 的强大能力,所谓内部 DSL,即使用 Kotlin 语言开发的,解决特定领域问题,具备独特代码结构的 API。
在代码中拼接 SQL 字符串一直是各位程序员心中的痛,Ktorm 提供了强类型的 DSL,让我们可以使用更安全和简便的方式编写 SQL。下面是一个使用 DSL 的例子,它查询每个部门的员工数量,并把部门按人数从高到低排序:
1 | database |
当你运行这段代码,Ktorm 会自动执行一条 SQL,生成的 SQL 如下:
1 | select t_department.name as t_department_name, count(t_employee.id) |
这就是 Kotlin 的魔法,使用 Ktorm 写查询十分地简单和自然,所生成的 SQL 几乎和 Kotlin 代码一一对应。并且,Ktorm 是强类型的,编译器会在你的代码运行之前对它进行检查,IDE 也能对你的代码进行智能提示和自动补全。
除了查询以外,Ktorm 的 DSL 还支持插入和修改数据,比如向表中插入一名新员工:
1 | database.insert(Employees) { |
生成 SQL:
1 | insert into t_employee (name, job, manager_id, hire_date, salary, department_id) |
给名为 vince 的员工加一个小目标的薪水:
1 | database.update(Employees) { |
生成 SQL:
1 | update t_employee set salary = salary + ? where name = ? |
在前面给 vince 加薪的过程中,细心的同学可能会发现我们很自然地使用了一个加号:it.salary + 100000000。然而,Employees.salary 的类型是 Column<Long>,我们怎么能把它和一个数字相加呢。这是因为 Kotlin 允许我们对运算符进行重载,使用 operator 关键字修饰的名为 plus 的函数定义了一个加号运算符。当我们对一个 Column 使用加号时,Kotlin 实际上调用了 Ktorm 中的这个 plus 函数:
1 | operator fun <T : Number> Column<T>.plus(argument: T): BinaryExpression<T> { |
上面的函数重载了加号运算符,但它并没有真正执行加法运算,它只是返回了一个 SQL 表达式,这个表达式最终会被 SqlFormatter 翻译为 SQL 中的加号。通过这种方式,Ktorm 得以将 Kotlin 中的四则运算符翻译为 SQL 中的相应符号。
除了加号以外,Ktorm 还重载了许多常用的运算符,它们包括加号、减号、一元加号、一元减号、乘号、除号、取余、取反等。下面的例子使用取余符号 % 查询数据库中 ID 为奇数的员工:
1 | val query = database.from(Employees).select().where { Employees.id % 2 eq 1 } |
生成 SQL:
1 | select * from t_employee where (t_employee.id % ?) = ? |
通过运算符重载,Ktorm 能够将 Kotlin 中四则运算符翻译为 SQL 中的相应符号。但是 Kotlin 的运算符重载还有许多的限制,比如:
equals 方法)的返回值类型必须是 Boolean。然而,为了将 Kotlin 中的运算符翻译到 SQL,Ktorm 要求运算符函数必须返回一个 SqlExpression,以记录我们的表达式的语法结构(比如上文中的 plus 函数)。like。天无绝人之路,Kotlin 提供了 infix 修饰符,使用 infix 修饰的函数,在调用时可以省略点和括号,这为我们开启了另一个思路。比如,使用 infix 关键字修饰 eq 函数,用来支持判等操作,这个 eq 函数我们再前面已经用过许多次:
1 | infix fun <T : Any> Column<T>.eq(expr: Column<T>): BinaryExpression<Boolean> { |
除了 eq 函数外,Ktorm 还提供了许多常用的运算符函数,它们包括 and、or、gt、lt、like 等。不仅如此,我们还能通过 infix 关键字定义自己特殊的运算符,比如 PostgreSQL 中的 ilike 运算符就可以定义为这样的一个 infix 函数:
1 | infix fun Column<*>.ilike(argument: String): ILikeExpression { |
有了这个 ilike 函数,接下来就只需要在 SqlFormatter 中把这个 ILikeExpression 翻译为合适的 SQL 就可以了,Ktorm 给我们提供了足够的灵活性,具体可以参考自定义运算符相关的文档。
除了 SQL DSL 以外,Ktorm 还提供了一套名为“实体序列”的 API,用来从数据库中获取实体对象。正如其名字所示,它的风格和使用方式与 Kotlin 标准库中的序列 API 及其类似,它提供了许多同名的扩展函数,比如 filter、map、reduce 等。
要使用实体序列 API,我们首先要定义实体类,并把表对象与实体类进行绑定:
1 | interface Employee : Entity<Employee> { |
完成 ORM 绑定后,我们就可以使用实体序列的各种方便的扩展函数。比如获取部门 1 中工资超过一千的所有员工对象:
1 | val employees = database.employees |
可以看到,实体序列的用法几乎与 kotlin.sequences.Sequence 完全一样,不同的仅仅是在 lambda 表达式中的等号 == 和大于号 > 被这里的 eq 和 gt 函数代替了而已。
我们还能使用 mapColumns 函数筛选需要的列,而不必把所有的列都查询出来,以及使用 sortedBy 函数把记录按指定的列进行排序。下面的代码获取部门 1 中工资超过一千的所有员工的名字,并按其工资的高低从大到小排序:
1 | val names = database.employees |
生成的 SQL 正如我们所料:
1 | select t_employee.name |
不仅如此,我们还能使用聚合功能,获取每个部门的平均工资:
1 | val averageSalaries = database.employees |
生成 SQL:
1 | select t_employee.department_id, avg(t_employee.salary) |
使用 Ktorm 的实体序列 API,可以让我们的数据库操作看起来就像在使用 Kotlin 中的集合一样。值得注意的是,实体序列 API 并没有真正实现 Kotlin 中的 Sequence 接口,Ktorm 只不过是设计了一套与其命名相似函数,以降低用户学习的成本,同时提供与 Kotlin 集合操作体验一致的编码风格。
在本文中,我们结合 Kotlin 的一些语法特性,探索了 Ktorm 框架中的许多设计细节。我们学习了如何使用扩展函数为 Ktorm 增加更多数据类型的支持、如何使用强类型的 DSL 编写 SQL、如何使用运算符重载和 infix 关键字为 Ktorm 扩展更多的运算符、以及如何使用实体序列 API 像集合一样操作数据库等。通过对这些细节的探讨,我们看到了 Ktorm 是如何充分利用 Kotlin 的优秀语法特性,帮助我们写出更优雅的、更具 Kotlin 风味的数据库操作代码。
Enjoy Ktorm, enjoy Kotlin!
]]>然而,切换到 Kotlin 之后,你还在用 MyBatis 吗?MyBatis 作为一个 Java 的 SQL 映射框架,虽然在国内使用人数众多,但是也受到了许多吐槽。使用 MyBatis,你必须要忍受在 XML 里写 SQL 这种奇怪的操作,以及在众多 XML 与 Java 接口文件之间跳来跳去的麻烦,以及往 XML 中传递多个参数时的一坨坨 @Param 注解(或者你使用 Map?那就更糟了,连基本的类型校验都没有,参数名也容易写错)。甚至,在与 Kotlin 共存的时候,还会出现一些奇怪的问题,比如: Kotlin 遇到 MyBatis:到底是 Int 的错,还是 data class 的错?。
这时,你可能想要一款专属于 Kotlin 的 ORM 框架。它可以充分利用 Kotlin 的各种优良特性,让我们写出更加 Kotlin 的代码。它应该是轻量级的,只需要添加依赖即可直接使用,不需要各种麻烦的配置文件。它的 SQL 最好可以自动生成,不需要像 MyBatis 那样每条 SQL 都自己写,但是也给我们保留精确控制 SQL 的能力,不至于像 Hibernate 那样难以进行 SQL 调优。
如果你真的这么想的话,Ktorm 可能会适合你。Ktorm 是直接基于纯 JDBC 编写的高效简洁的 Kotlin ORM 框架,它提供了强类型而且灵活的 SQL DSL 和方便的序列 API,以减少我们操作数据库的重复劳动。当然,所有的 SQL 都是自动生成的。本文的目的就是对 Ktorm 进行介绍,帮助我们快速上手使用。
你可以在 Ktorm 的官网上获取更详细的使用文档,如果使用遇到问题,还可以在 GitHub 提出 issue。如果 Ktorm 对你有帮助的话,请在 GitHub 留下你的 star,也欢迎加入我们,共同打造 Kotlin 优雅的 ORM 解决方案。
Ktorm 官网:https://www.ktorm.org
GitHub 地址:https://github.com/kotlin-orm/ktorm
还记得我们刚开始学编程的时候写的第一个程序吗,现在我们先从 Ktorm 的 “Hello, World” 开始,了解如何快速地搭建一个使用 Ktorm 的项目。
Ktorm 已经发布到 maven 中央仓库和 jcenter,因此,如果你使用 maven 的话,首先需要在 pom.xml 文件里面添加一个依赖:
1 | <dependency> |
或者 gradle:
1 | compile "org.ktorm:ktorm-core:${ktorm.version}" |
在使用 Ktorm 之前,我们需要让它能够了解我们的表结构。假设我们有两个表,他们分别是部门表 t_department 和员工表 t_employee, 它们的建表 SQL 如下,我们要如何描述这两个表呢?
1 | create table t_department( |
一般来说,Ktorm 使用 Kotlin 中的 object 关键字定义一个继承 Table 类的对象来描述表结构,上面例子中的两个表可以像这样在 Ktorm 中定义:
1 | object Departments : Table<Nothing>("t_department") { |
可以看到,Departments 和 Employees 都继承了 Table,并且在构造函数中指定了表名,Table 类还有一个泛型参数,它是此表绑定到的实体类的类型,在这里我们不需要绑定到任何实体类,因此指定为 Nothing 即可。表中的列则使用 val 关键字定义为表对象中的成员属性,列的类型使用 int、long、varchar、date 等函数定义,它们分别对应了 SQL 中的相应类型。
定义好表结构后,我们就可以使用 Database.connect 函数连接到数据库,然后执行一个简单的查询:
1 | fun main() { |
这就是一个最简单的 Ktorm 项目,这个 main 函数中只有短短三四行代码,但是你运行它时,它却可以连接到数据库,自动生成一条 SQL select * from t_employee,查询表中所有的员工记录,然后打印出他们的名字。因为 select 函数返回的查询对象重载了迭代运算符,所以你可以在这里使用 for-each 循环的语法。
让我们在上面的查询里再增加一点筛选条件:
1 | database |
生成的 SQL 如下:
1 | select t_employee.name as t_employee_name |
这就是 Kotlin 的魔法,使用 Ktorm 写查询十分地简单和自然,所生成的 SQL 几乎和 Kotlin 代码一一对应。并且,Ktorm 是强类型的,编译器会在你的代码运行之前对它进行检查,IDE 也能对你的代码进行智能提示和自动补全。
实现基于条件的动态查询也十分简单,因为都是纯 Kotlin 代码,直接使用 if 语句就好,比 MyBatis 在 XML 里面写 <if> 标签好太多。
1 | val query = database |
聚合查询:
1 | val t = Employees.aliased("t") |
Union:
1 | val query = database |
多表连接查询:
1 | data class Names(val name: String?, val managerName: String?, val departmentName: String?) |
插入:
1 | database.insert(Employees) { |
更新:
1 | database.update(Employees) { |
删除:
1 | database.delete(Employees) { it.id eq 4 } |
这就是 Ktorm 提供的 SQL DSL,使用这套 DSL,我们可以使用纯 Kotlin 代码来编写查询,不再需要在 XML 中写 SQL,也不需要在代码中拼接 SQL 字符串。而且,强类型的 DSL 还能让我们获得一些额外的好处,比如将一些低级的错误暴露在编译期,以及 IDE 的智能提示和自动补全。最重要的是,它生成的 SQL 几乎与我们的 Kotlin 代码一一对应,因此虽然我们的 SQL 是自动生成的,我们仍然对它拥有绝对的控制。
这套 DSL 几乎可以覆盖我们工作中常见的所有 SQL 的用法,比如 union、联表、聚合等,甚至对嵌套查询也有一定的支持。当然,肯定也有一些暂时不支持的用法,比如某些数据库中的特殊语法,或者十分复杂的查询(如相关子查询)。这其实十分罕见,但如果真的发生,Ktorm 也提供了一些解决方案:
ktorm-support-mysql。当然,我们也能自己编写扩展。更多 SQL DSL 的用法,请参考 Ktorm 的具体文档。
前面我们已经介绍了 SQL DSL,但是如果只有 DSL,Ktorm 还远不能称为一个 ORM 框架。接下来我们将介绍实体类的概念,了解如何将数据库中的表与实体类进行绑定,这正是 ORM 框架的核心:对象 - 关系映射。
我们仍然以前面的部门表 t_department 和员工表 t_employee 为例,创建两个 Ktorm 的实体类,分别用来表示部门和员工这两个业务概念:
1 | interface Department : Entity<Department> { |
可以看到,Ktorm 中的实体类都继承了 Entity<E> 接口,这个接口为实体类注入了一些通用的方法。实体类的属性则使用 var 或 val 关键字直接定义即可,根据需要确定属性的类型及是否为空。
有一点可能会违背你的直觉,Ktorm 中的实体类并不是 data class,甚至也不是一个普通的 class,而是 interface。这是 Ktorm 的设计要求,通过将实体类定义为 interface,Ktorm 才能够实现一些特别的功能,以后你会了解到它的意义。
众所周知,接口并不能实例化,既然实体类被定义为接口,我们要如何才能创建一个实体对象呢?其实很简单,只需要像下面这样,假装它有一个构造函数:
1 | val department = Department() |
有心的同学应该已经发现,上面定义实体类接口的时候,还为这两个接口都增加了一个伴随对象。这个伴随对象重载了 Kotlin 中的 invoke 操作符,因此可以使用括号像函数一样直接调用。在 Ktorm 的内部,我们使用了 JDK 的动态代理创建了实体对象。
还记得在上一节中我们定义的两个表对象吗?现在我们已经有了实体类,下一步就是把实体类和前面的表对象进行绑定。这个绑定其实十分简单,只需要在声明列之后继续链式调用 bindTo 函数或 references 函数即可,下面的代码修改了前面的两个表对象,完成了 ORM 绑定:
1 | object Departments : Table<Department>("t_department") { |
命名规约:强烈建议使用单数名词命名实体类,使用名词的复数形式命名表对象,如:Employee/Employees、Department/Departments。
把两个表对象与修改前进行对比,我们可以发现两处不同:
Table 类的泛型参数,我们需要指定为实体类的类型,以便 Ktorm 将表对象与实体类进行绑定;在之前,我们设置为 Nothing 表示不绑定到任何实体类。bindTo 或 references 函数将该列与实体类的某个属性进行绑定;如果没有这个调用,则不会绑定到任何属性。列绑定的意义在于,通过查询从数据库中获取实体对象的时候,Ktorm 会根据我们的绑定配置,将某个列的数据填充到它所绑定的属性中去;在将实体对象中的修改更新到数据库中的时候(使用 flushChanges 函数),Ktorm 也会根据我们的绑定配置,将某个属性的变更,同步更新到绑定它的那个列。
完成列绑定后,我们就可以使用序列 API 对实体进行各种灵活的操作。我们先给 Database 定义两个扩展属性,它们使用 sequenceOf 函数创建序列对象并返回。这两个属性可以帮助我们提高代码的可读性:
1 | val Database.departments get() = this.sequenceOf(Departments) |
下面的代码使用 find 函数从序列中根据名字获取一个 Employee 对象:
1 | val employee = database.employees.find { it.name eq "vince" } |
我们还能使用 filter 函数对序列进行筛选,比如获取所有名字为 vince 的员工:
1 | val employees = database.employees.filter { it.name eq "vince" }.toList() |
find 和 filter 函数都接受一个 lambda 表达式作为参数,使用该 lambda 的返回值作为条件,生成一条查询 SQL。可以看到,生成的 SQL 自动 left jion 了关联表 t_department:
1 | select * |
将实体对象保存到数据库:
1 | val employee = Employee { |
将内存中实体对象的变化更新到数据库:
1 | val employee = database.employees.find { it.id eq 2 } ?: return |
从数据库中删除实体对象:
1 | val employee = database.employees.find { it.id eq 2 } ?: return |
更多实体 API 的用法,可参考列绑定和实体查询相关的文档。
可以看到,只需要将表对象与实体类进行绑定,我们就可以使用这些方便的函数,大部分对实体对象的增删改查操作,都只需要一个函数调用即可完成,但 Ktorm 能做到的,还远不止于此。
Ktorm 提供了一套名为”实体序列”的 API,用来从数据库中获取实体对象。正如其名字所示,它的风格和使用方式与 Kotlin 标准库中的序列 API 极其类似,它提供了许多同名的扩展函数,比如 filter、map、reduce 等。
Ktorm 的实体序列 API,大部分都是以扩展函数的方式提供的,这些扩展函数大致可以分为两类,它们分别是中间操作和终止操作。
这类操作并不会执行序列中的查询,而是修改并创建一个新的序列对象,比如 filter 函数会使用指定的筛选条件创建一个新的序列对象。下面使用 filter 获取部门 1 中的所有员工:
1 | val employees = database.employees.filter { it.departmentId eq 1 }.toList() |
可以看到,用法几乎与 kotlin.sequences 完全一样,不同的仅仅是在 lambda 表达式中的等号 == 被这里的 eq 函数代替了而已。filter 函数还可以连续使用,此时所有的筛选条件将使用 and 运算符进行连接,比如:
1 | val employees = database.employees |
生成 SQL:
1 | select * |
使用 sortedBy 或 sortedByDescending 对序列中的元素进行排序:
1 | val employees = database.employees.sortedBy { it.salary }.toList() |
使用 drop 和 take 函数进行分页:
1 | val employees = database.employees.drop(1).take(1).toList() |
实体序列的终止操作会马上执行一个查询,获取查询的执行结果,然后执行一定的计算。for-each 循环就是一个典型的终止操作,下面我们使用 for-each 循环打印出序列中所有的员工:
1 | for (employee in database.employees) { |
生成的 SQL 如下:
1 | select * |
toCollection、toList 等方法用于将序列中的元素保存为一个集合:
1 | val employees = database.employees.toCollection(ArrayList()) |
mapColumns 函数用于获取指定列的结果:
1 | val names = database.employees.mapColumns { it.name } |
除此之外,mapColumns 还可以同时获取多个列的结果,这时我们只需要在闭包中使用 tupleOf 包装我们的这些字段,函数的返回值也相应变成了 List<TupleN<C1?, C2?, .. Cn?>>:
1 | database.employees |
生成 SQL:
1 | select t_employee.id, t_employee.name |
其他我们熟悉的序列函数也都支持,比如 fold、reduce、forEach 等,下面使用 fold 计算所有员工的工资总和:
1 | val totalSalary = database.employees |
实体序列 API 不仅可以让我们使用类似 kotlin.sequences 的方式获取数据库中的实体对象,它还支持丰富的聚合功能,让我们可以方便地对指定字段进行计数、求和、求平均值等操作。
下面使用 aggregateColumns 函数获取部门 1 中工资的最大值:
1 | val max = database.employees |
如果你希望同时获取多个聚合结果,只需要在闭包中使用 tupleOf 包装我们的这些聚合表达式即可,此时函数的返回值就相应变成了 TupleN<C1?, C2?, .. Cn?>。下面的例子获取部门 1 中工资的平均值和极差:
1 | val (avg, diff) = database.employees |
生成 SQL:
1 | select avg(t_employee.salary), max(t_employee.salary) - min(t_employee.salary) |
除了直接使用 aggregateColumns 函数以外,Ktorm 还为序列提供了许多方便的辅助函数,他们都是基于 aggregateColumns 函数实现的,分别是 count、any、none、all、sumBy、maxBy、minBy、averageBy。
下面改用 maxBy 函数获取部门 1 中工资的最大值:
1 | val max = database.employees |
除此之外,Ktorm 还支持分组聚合,只需要先调用 groupingBy,再调用 aggregateColumns。下面的代码可以获取所有部门的平均工资,它的返回值类型是 Map<Int?, Double?>,其中键为部门 ID,值是各个部门工资的平均值:
1 | val averageSalaries = database.employees |
生成 SQL:
1 | select t_employee.department_id, avg(t_employee.salary) |
在分组聚合时,Ktorm 也提供了许多方便的辅助函数,它们是 eachCount(To)、eachSumBy(To)、eachMaxBy(To)、eachMinBy(To)、eachAverageBy(To)。有了这些辅助函数,上面获取所有部门平均工资的代码就可以改写成:
1 | val averageSalaries = database.employees |
除此之外,Ktorm 还提供了 aggregate、fold、reduce 等函数,它们与 kotlin.collections.Grouping 的相应函数同名,功能也完全一样。下面的代码使用 fold 函数计算每个部门工资的总和:
1 | val totalSalaries = database.employees |
更多实体序列 API 的用法,可参考实体序列和序列聚合相关的文档。
本文从一个 “Hello, World” 程序开始,对 Ktorm 的几大特性进行了介绍,它们分别是 SQL DSL、实体类与列绑定、实体序列 API 等。有了 Ktorm,我们就可以使用纯 Kotlin 代码方便地完成数据持久层的操作,不需要再使用 MyBatis 烦人的 XML。同时,由于 Ktorm 是专注于 Kotlin 语言的框架,因此没有兼容 Java 的包袱,能够让我们更加充分地使用 Kotlin 各种优越的语法特性,写出更加优雅的代码。既然语言都已经切换到 Kotlin,为何不尝试一下纯 Kotlin 的框架呢?
Enjoy Ktorm, enjoy Kotlin!
]]>本文来自我的知乎回答:找到编译器的bug是种怎样的体验? - 知乎
emmm…这个问题下面真的是大佬云集,萌新感到好忐忑…
前段时间在使用 Kotlin 开发一个 ORM 框架(广告慎入,Ktorm:专注于 Kotlin 的 ORM 框架),当时我的代码大概是这样的,定义了一个 Foo 接口,在这个接口里面写了个默认实现的 bar() 方法:
1 | interface Foo { |
怎么样,看起来是不是稳如狗?然而,这段代码在运行的时候,却喷了我一脸异常:
1 | Exception in thread "main" java.lang.InternalError: Malformed class name |
风中凌乱…我不就是想输出一下匿名对象的类名吗,这个 InternalError 是什么鬼…
惊讶之余,冷静下来好好理了理 Kotlin 生成 class 的规则,终于明白过来。
众所周知,在 Java 中,interface 里面是不能有方法实现的(Java 8 以前),然而,Kotlin 却可以直接在接口里面实现方法。我们知道,Kotlin 最终也是要编译成 Java 字节码,既然 Java 本身都不支持这种操作,Kotlin 是怎么做到的呢?
反编译 Kotlin 生成的字节码就可以看到,在编译出来的 interface Foo 中,bar 方法仍然是 abstract 的,并没有实现。但是,Kotlin 另外生成了一个 Foo$DefaultImpls 类,在这个类里面有一个静态方法,这个方法的签名是:
1 | public static void bar(Foo $this) |
这个方法里面的字节码,就是我们的 bar() 方法的默认实现了。这样,当一个 Kotlin 的类实现了 Foo 接口时,编译器就会自动为我们插入一个 bar() 方法的实现,这个实现只是简单调用了 Foo$DefaultImpls 里面的静态方法:
1 |
|
这就是 Kotlin 中接口默认方法的实现原理。
然而这跟前面的 bug 又有什么关系…
我们回过头来看刚刚出 bug 的代码,可以看到一个 object : Any() { },这应该会生成一个匿名内部类,看下编译结果,可以知道这个匿名内部类的名字是 Foo$bar$obj$1,这应该没什么特别的。
然后顺着异常栈去到 JDK 的 Class 类里面,看源码,可以看到报错的地方是这样的:
1 | private String getSimpleBinaryName() { |
额,好像找到原因了…
回到前面提到的匿名内部类 Foo$bar$obj$1,因为 bar() 方法是在 Foo$DefaultImpls 中实现的,所以对这个匿名类获取 enclosingClass 毫无疑问就是 Foo$DefaultImpls 了,然后在 substring 的时候就 GG 了…
最后,根据我粗浅的理解,应该可以得出结论,这个 bug 的根源是 Kotlin 在编译这个匿名内部类的时候生成的名字有误,如果生成的名字是 Foo$DefaultImpls$bar$obj$1 的话,bug 就不会发生。带着这个疑惑,我去 Kotlin issue 上面找了找,果然已经有人提出过这个问题,然而这个 issue 至今都是 open 状态,并没有得到解决,难道是这个 bug 会牵扯到其他地方?有兴趣的同学可以去看一看:Names for anonymous classes in interfaces are malformed : KT-16727
最终,bug 的原因是找到了,那在 Kotlin 修复这个 bug 之前应该怎么办呢?我们当然只能想办法绕过了,比如避免在接口的默认实现方法中使用匿名内部类,lambda 也不行,因为 Kotlin 的 lambda 也会编译成匿名类…
BTW,说到编译器的 bug,之前在使用 Java 8 的 lambda 的时候也遇到过一个,当时还在知乎吐槽了一下,这里也贴个链接,仅作记录:此处的lambda为什么不能用方法引用表示 - 知乎
以上
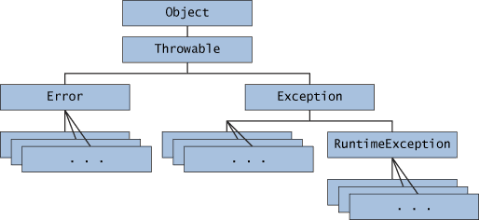
]]>众所周知,Java 的所有异常都派生自 Throwable 类,在继承结构上,从 Throwable 派生出了 Error 和 Exception 两大类。其中,Error 表示系统级别的严重程序错误,一般由 JVM 抛出,我们也不应该捕获这类异常,用户自定义的异常一般都派生自 Exception 类。
从是否被编译器强制检查一点,异常又可分为受检异常(Checked Exception)和未受检异常(Unchecked Exception)。未受检异常派生自 Error 或者 RuntimeException,表示不可恢复的程序错误,典型例子有 AssertionError、NullPointerException 等,编译器不会强制我们捕获这类异常。受检异常则是除了 Error/RuntimeException 之外,派生自 Throwable 或者 Exception 的其他异常,比如 IOException、SQLException 等。如果一个方法声明自己可能抛出受检异常,那么编译器会强制它的调用者必须使用 try-catch 捕获此异常,或者在自己的方法中加上 throws 声明将异常继续传播给外界。
多年以来,Java 中受检异常的设计一直颇受争议,反对者认为,受检异常容易破坏方法声明的兼容性,会使代码的可读性降低,还增加开发的工作量等等。当然也有一些支持者,他们认为受检异常可以强迫程序员去思考,有助于他们写出更健壮的代码,可以参考王垠的文章「Kotlin 和 Checked Exception」。
在这里,我不想继续讨论受检异常到底是好还是坏,我只想以这个为切入点,随便讨论一点关于 Java 的八卦。
上面讲过,如果一个方法可能抛出受检异常,就必须在方法上加上 throws 声明,也就是说,如果方法上没有 throws 声明,这个方法就不可能抛出受检异常吗?按照 Java 的语言规范,这当然不可能,否则受检异常不就名不符实了吗?
当然说话也不能这么绝对,作为一个程序员,我们在自认为不可能的地方找到的 bug 还少吗?Test first,我们先来看一段测试代码。
1 | interface SneakyThrows { |
这是一个接口和一个测试方法。这个 SneakyThrows 接口自称它会抛出一个 IOException,然而它的方法上却没有 throws 声明。测试方法接受一个实现了 SneakyThrows 接口的对象,调用接口上的 sneakyThrow 方法,如果接口方法真的抛出了 IOException,则输出 success 字样,否则会抛出异常,测试失败。那么,聪明的你,有没有办法实现这样一个接口,使测试能够成功呢?
当然有,而且还不止一种方法!
在 Java 里,说到黑科技,大家总是会首先想到 sun.misc.Unsafe,这个类大量出现在 JDK 源码以及各种第三方类库的源码中,用于实现一些奇奇怪怪的功能。那么它能不能用来抛出一个受检异常呢?当然能,Unsafe 中刚好有一个 throwException 方法可以实现这个功能。可惜的是,获取 Unsafe 对象只有一个 Unsafe.getUnsafe() 方法,而这个方法中加了对调用者的检查,只有 jdk 中的类才能调用这个方法,否则将抛出 SecurityException。
但是我们还有反射,只要 Unsafe 对象是保存在一个 Java 的字段中,反射就可以直接拿到这个对象,无视访问权限以及安全检查。下面这段代码,首先通过反射得到了 Unsafe 对象,然后调用它的 throwException 方法,成功抛出了一个受检异常。
1 | class UnsafeSneakyThrows implements SneakyThrows { |
小伙伴们可以运行一下,这段代码完全做到我们之前认为不可能的事情,在一个没有 throws 声明的方法里抛出受检异常!这时,有心的小伙伴应该就能明白过来,所谓的受检不受检,其实只是一个编译器的魔法,JVM 是完全不关心的。这也是为什么基于 JVM 的其他语言,比如 Scala、Groovy 之类,完全抛弃了受检异常的设计,却能运行在 JVM 上,并且能和 Java 很好地兼容。另外,学过 C++ 的同学应该也知道,在 C++ 里面,异常并不像 Java 一样有一个共同的基类,C++ 的 throw 语句可以抛出任何东西,甚至直接抛出一个 int 之类的值类型,当然这是题外话。
通过 Unsafe,我们能玩的黑魔法还有很多,比如分配一段非托管的直接内存、绕过 Java 的类初始化机制直接创建一个未初始化的对象、通过偏移量直接修改任何对象内的字段、以及硬件级别的原子操作 CAS 等。正因如此,它的身影也在 JDK 源码和各种第三方类库中频繁出现。比如 concurrent 包中使用它实现了各种线程同步相关的工具类以及 AtomicXxx 系的各种无锁的原子操作;nio 使用它获得了直接操作裸内存的能力;netty 也因为它得以直接操作堆外内存,大大地提升了性能;各类序列化库也使用它绕过类初始化机制、以方便地实现反序列化。
然而,这种大杀器一般都会有很大的副作用,比如分配的非托管内存,如果不注意释放,很容易就造成内存泄露,其他的操作也往往是高危操作,正如其 Unsafe 的名字。有消息称,在 JDK9 中,随着新的模块系统的推出,真正杜绝了应用直接使用 Unsafe 类,到时这个黑魔法就不管用咯,可以看看 R 大在知乎的回答:「为什么JUC中大量使用了sun.misc.Unsafe 这个类,但官方却不建议开发者使用? - RednaxelaFX的回答 - 知乎」。
泛型也是那些黑 Java 的人的主要喷点之一。在 Java 中,泛型也只是编译器的语法糖,JVM 中并不保留泛型的类型信息,其名曰「类型擦除」。JDK5 推出时,Java 已在各行各业广泛使用,采用类型擦除的泛型设计也是出于兼容性考虑,否则就要像 C# 一样,同时存在 System.Collections 和 System.Collections.Generic 两套集合框架。关于泛型的更多细节,也可以看看 R 大的文章「Reifiable generics与Type erasure generics各有怎样的优点与缺点? - RednaxelaFX的回答 - 知乎」。
然而,采用类型擦除除了大家都说烂了的那些坏处之外,还有一些不为人知的坑,比如下面这段代码就是。
1 | class GenericSneakyThrows implements SneakyThrows { |
这里定义了一个泛型声明为 <X extends Throwable> 方法,在内部将传入的 Throwable 强转为 X 之后再抛出,X 的具体类型取决于调用这个方法时指定的类型参数。在这里,只要将类型参数指定为 RuntimeException,然后不管传入一个什么异常,都可以直接抛出去,而不用 throws 声明。什么,你说为什么 IOException 可以强转成 RuntimeException?当然是因为类型擦除啊,由于类型擦除的存在,sneakyThrow0 在被调用的时候,X 在运行时实际上是擦除为 Throwable 类型,从 IOException 转成 Throwable 一点问题都不会有。
所以说,基于类型擦除的泛型,和受检异常的设计实际上是冲突的,如果说上面提到的 Unsafe 是内部 API,可以不允许外界调用,那么,在类型擦除和受检异常共存的 Java 里,永远也不可能解决这个问题。
顺便一提,在 JDK8 中,由于 lambda 的引入,改变了类型推断算法,上面代码中的类型参数其实是可以省略的,直接 this.sneakyThrow0(new IOException()) 即可。
在很多文章里面,都推荐大家在使用反射的时候,用 Constructor.newInstance() 代替 Class.newInstance() 创建对象,这是为什么呢?我们先看看下面这段代码。
1 | class ConstructorSneakyThrows implements SneakyThrows { |
和上面两个例子一样,上面这段代码也可以抛出一个受检异常。我们首先写了一个 ConstructorThrowable 类,这个类有一个无参构造方法,在构造方法里面我们抛出了一个 IOException,因此在调用 Class.newInstance() 的时候就把这个异常传播了出去,从而绕过了编译器的检查。
那么,为什么 Constructor.newInstance() 就不会有这个问题呢?对比这两者的签名就可以发现,它的 throws 列表中多了一个 InvocationTargetException,在构造方法的执行过程中如果发生了异常,这个异常会被包装为 InvocationTargetException 再次抛出。
这两个方法明明有相同的作用,但是在异常方面却有微妙的差别。查看 JDK 源码我们可以看到,Class.newInstance() 底层其实就是先获取到 Constructor 对象,然后再把实际的操作代理给 Constructor.newInstance()。然而,在这个过程中,它捕获了 InvocationTargetException,然后使用 Unsafe 将其包装的 targetException 直接抛出。
为什么 Class.newInstance() 要多次一举呢?这其实是历史原因导致的。Java 的反射 API 是在 1.2 版本引入的,而 Class 类在之前就有了,如果在 Class.newInstance() 方法的 throws 声明中也加上 InvocationTargetException 的话,由于这个异常是受检异常,就会导致基于旧版 JDK 写的代码都不能通过编译。所以为了兼容性考虑,只能使用 Unsafe 来传播构造方法中产生的异常。这也是一个证明受检异常是设计失误的例子,即容易破坏兼容性、妨碍 API 的演化。
具体的细节,在 Class.newInstance() 的 Javadoc 中已经有介绍,Stack Overflow 上也有相关的讨论,「java - Why is Class.newInstance() “evil”? - Stack Overflow」。
在 JDK5 里面,Thread 类一口气废弃了好几个方法,它们就是 suspend/resume/stop 系列。当然,废弃归废弃,只要我们有充分的理由,也不是不能用它们。
1 | class ThreadStopSneakyThrows implements SneakyThrows { |
如你所见,接收一个 Throwable 参数的 Thread.stop() 方法也可以用来实现 SneakyThrows,抛出一个受检异常。stop() 方法的作用是使指定线程产生一个异常,从而强行终止该线程的执行。在这里,我们使当前线程产生一个 IOException,以达到我们的目的。那么它为什么被废弃了呢?JDK 文档里面有详细的解释。
This method is inherently unsafe. Stopping a thread with Thread.stop causes it to unlock all of the monitors that it has locked (as a natural consequence of the unchecked
ThreadDeathexception propagating up the stack). If any of the objects previously protected by these monitors were in an inconsistent state, the damaged objects become visible to other threads, potentially resulting in arbitrary behavior. Many uses ofstopshould be replaced by code that simply modifies some variable to indicate that the target thread should stop running. The target thread should check this variable regularly, and return from its run method in an orderly fashion if the variable indicates that it is to stop running. If the target thread waits for long periods (on a condition variable, for example), theinterruptmethod should be used to interrupt the wait.
简单来说,如果一个线程已经获得了某个锁,正在执行某些互斥操作,stop() 方法会强行使这个线程失去锁,而此时,它的操作可能还没有执行完成,这就可能使变量处于不一致的状态,造成线程安全问题。
嘛,反正这个方法已经废弃了,再多说也没什么意义。值得一提的是,在 JDK8 里,带 Throwable 参数的 Thread.stop() 方法已经改成直接抛出 UnsupportedOperationException,完全不能使用了,只有无参数的重载版本还仍可使用(无参版本默认抛出 ThreadDeath)。所以上面那段代码,只有在 JDK7 及以下才有效,在 JDK8 中并不能通过测试。
好了,扯淡结束。本文简单介绍了 Java 中的受检异常和未受检异常的区别,指出受检异常只是编译器的魔法、JVM 底层并不关心,并给出了四种绕过编译器检查,在任何地方都可抛出受检异常的方法。在介绍这四种方法的时候,随便讲了一些与之相关的八卦。
我的观点是,学习一门编程语言,了解一下这门语言的八卦还是很有必要的。当你知道它都有那些缺点,你就会思考,为什么当初要这样设计,你就会明白,所有的缺点,其实都是工程上的妥协。
程序员啊,还是要保持这一颗八卦的心。
荆轲刺秦王。
]]>Comparable 是 Java 中非常常用的一个接口,但是其中也有一些值得深究的细节。我们以「德州扑克」游戏的业务场景为例进行说明。「德州扑克」是一款风靡世界的扑克游戏,要实现这个游戏,首先要对系统进行建模,我们可能会写出这样的一段代码:
1 | public enum PokerSuit { |
PokerCard 是一个十分简单的模型类,但它足以描述游戏中的一张扑克牌。其中,number 表示扑克牌的点数,1 代表 A,11 ~ 13 代表 J ~ K;suit 表示扑克牌的花色,它是一个枚举类型;因为「德州扑克」中没有大王和小王,所以在这里不作考虑。
按照约定,如果我们需要把这个类用在基于哈希集合中,就必须重写它的 hashCode 和 equals 方法。这个容易,重写就是了:
1 |
|
另外,扑克牌之间需要比较大小,所以我们需要实现 Comparable 接口以支持比较操作。「德州扑克」比较牌的大小是单纯比较点数,忽略花色的,所以代码可能是这样:
1 | public class PokerCard implements Comparable<PokerCard> { |
到此为止,一切都是那么和谐,在设计上,这个类似乎没有任何问题,事实上,在大部分情况下,它也是完全可以正常工作的。
那么,现在我们需要表示一个「牌型」的概念,所谓「牌型」,在德州扑克里面,即是在玩家的手牌与桌面的公共牌中选取五张牌所组成的一个集合,在比牌时,「牌型」最大的玩家即可赢得奖池。在这个定义中,我们可以知道,「牌型」是一个集合,而且需要支持比较操作,因此我们可以让它实现 Set 和 Comparable 接口。在实际操作中,我们一般不会直接实现 Set 接口,而是选择继承 AbstractSet 类以减少代码量,因此,代码可能是这样的:
1 | public class PokerCombination |
在这里,我们省略了 compareTo 方法的具体代码,但是,为了方便实现比较操作, 在PokerCombination 类的内部实现中,采用了 SortedSet,这是一个有序的集合,在其中的元素都会按照其自然顺序(即 Comparable.compareTo 方法定义的顺序)进行排序,TreeSet 是它的一个常见的实现类。
现在我们添加一个测试方法,测试这个类的行为是否正确:
1 |
|
这个测试方法非常简单,它首先创建了一个集合,往里面添加了 5 张扑克牌,断言它的长度是 5,然后用这个集合构造了一个 PokerCombination 对象,再断言它的长度也是 5。就这样一个简单的测试,它几乎一定会运行成功,在很多人眼里,甚至都没有写这个它的必要。
然而,当你真的运行这个测试的时候,它却失败了,错误信息如下:
1 | java.lang.AssertionError: |
这是一个断言错误,发生在我们的第二次 assertEquals 调用时,我们期望 PokerCombination 的长度是 5,然而它却是 4。现在问题来了,为什么一个长度为 5 的集合,传入 PokerCombination 里面,却变成了 4 呢?这里面发生的事情,仅仅是将传入的集合复制到一个 SortedSet 里面而已。
我们尝试将 SortedSet 换成更为通用的 Set,将 TreeSet 换成 HashSet,发现测试能正常执行,但是换回 SortedSet 的时候,它又失败了,因此,问题一定与 SortedSet 有关。打开它的源码,查看 JavaDoc,我们看到了下面这段描述:
Note that the ordering maintained by a sorted set (whether or not an explicit comparator is provided) must be consistent with equals if the sorted set is to correctly implement the Set interface. (See the Comparable interface or Comparator interface for a precise definition of consistent with equals.) This is so because the Set interface is defined in terms of the equals operation, but a sorted set performs all element comparisons using its compareTo (or compare) method, so two elements that are deemed equal by this method are, from the standpoint of the sorted set, equal. The behavior of a sorted set is well-defined even if its ordering is inconsistent with equals; it just fails to obey the general contract of the Set interface.
大概解释一下:如果要使 SortedSet 正确表现出与普通的 Set 相同的行为,那么它内部元素的顺序关系必须要「与 equals 一致(consistent with equals)」。这是因为 Set 使用 equals 方法判断元素的等同性,而 SortedSet 使用的是 compareTo 方法,即如果 compareTo 方法返回 0,SortedSet 就认为这两个元素是相等的。当 compareTo 与 equals 的一致性不能满足时,SortedSet 的行为就会违背 Set 接口的通用约定。
那么,什么叫「与 equals 一致(consistent with equals)」呢,Comparable 接口的 JavaDoc 里面有明确的定义。对于任意非空变量 x 和 y,满足 (x.compareTo(y)==0) == (x.equals(y)),即认为 compareTo 与 equals 一致。任何实现了 Comparable,但是并没有满足这个条件的类,都应该在自己的文档中明确注明这一点。
It is strongly recommended, but not strictly required that (x.compareTo(y)==0) == (x.equals(y)). Generally speaking, any class that implements the Comparable interface and violates this condition should clearly indicate this fact. The recommended language is “Note: this class has a natural ordering that is inconsistent with equals.”
然而,Comparable 接口对这种一致性的约定也只是「建议」,而不是必须严格执行的规则。当然,这是可以理解的,毕竟在现实世界中,这种不一致也是存在的。就比如我们现在这个业务场景,当我们比较两张扑克牌是否相同,需要同时考虑花色和点数,当我们只是比较它们的大小时,就会忽略它们的花色。因此当 x.compareTo(y) == 0 时,x.equals(y) 是不确定的。这就是 compareTo 与 equals 不一致的情况,这种不一致是合理的。
JDK 标准库中也有这种不一致的情况,比如 BigDecimal 类。如果你创建一个 HashSet 实例,并且添加 new BigDecimal("1.0") 和 new BigDecimal("1.00"),这个集合就将包含两个元素,因为新增到集合中的两个 BigDecimal 实例,通过 equals 方法来比较时是不相等的。然而,如果你把 HashSet 换成 TreeSet,集合中将只包含一个元素,因为这两个实例在使用 compareTo 方法来比较时是相等的。
在大部分情况下,如果我们的类并没有遵守这种一致性,一般也没有什么问题。但是如果要把这个类用在有序集合中的时候,可能就需要做一点设计上的权衡。在「德州扑克」这个场景中,我们可以在 new TreeSet<>() 的时候,额外提供一个与 equals 一致的 Comparator,使这个集合能够正确地遵守通用的约定。如果项目中使用到 SortedSet 的地方不止这一处,我们也可以妥协,提供一个与 equals 一致的 compareTo 方法,但是在真正需要比较牌的大小的时候,使用另外的 compareIgnoreSuit 方法,比如:
1 | public class PokerCard implements Comparable<PokerCard> { |
这样改过代码之后,之前的那个测试当然能通过,讨论也已基本结束,但是,我们的思考却不应该止步于此。正如题目所言,我把这个称为一个「坑」,但是在 SortedSet 的文档描述中,它却是一个 well-defined feature. 虽然文档中已经有了「免责声明」,但还是有不止一人曾经跳入这个「坑」里面,究其原因,恐怕与 SortedSet 继承了 Set 脱离不了干系。
继承了一个接口,却不遵守这个接口的约定,这实在让人难以理解。既然 SortedSet 无法使用 equals 来判断元素的等同性,就应该另立门户,成为一个独立的接口,而不是选择继承 Set。根据里氏替换原则(Liskov Substitution Principle LSP),当我们把程序中的 Set 替换成其子接口 SortedSet 时,程序还应该能正常工作,SortedSet 并不能做到这一点,这正是其继承了 Set,却没有遵守 Set 的契约导致的。当然,标准库的设计者作出这个决策,应该也是权衡了利弊的结果,毕竟,直接继承 Set 可以方便地进行向上转型,方便使用者对 SortedSet 和其他的 Set 进行统一的处理。然而,如果我们把 SortedSet 独立为一个接口,也可以提供一个 asSet 视图方法,方便使用者在需要的时候将它视为一个 Set。因此我认为,选择让 SortedSet 继承 Set,是个弊大于利的决策。
以上只是对类库设计的一点拙见,班门弄斧,如果您有不同意见,欢迎讨论。
]]>在开始之前,我们先来念两句诗,代码如下:
1 | public static void main(String[] args) { |
上面代码的输出是:
1 | 岂因祸福避趋之 |
不对呀,反了反了,念诗都念错,姿势水平还是太低。怎么改呢,很简单,把两次 recitePoems 方法调用的参数调转过来就可以了? naïve,本文的目的是介绍黑科技,当然不会用这种寻常的办法解决问题。
不卖关子了,直接上代码吧:
1 | private static void doSomeMagic() throws Exception { |
接下来,只需要在 main 方法的开头调用这个名为 doSomeMagic 的膜法方法就好了:
1 | public static void main(String[] args) throws Exception { |
修改完毕之后,我们得到了期望的输出:
1 | 苟利国家生死以 |
那么,doSomeMagic 方法到底干了什么呢?很简单,它交换了 Boolean.TRUE 和 Boolean.FALSE 的值。为了能够重写它们的值,我们需要去掉它们的 final 修饰符,这就是 xxxField.getModifiers() & ~Modifier.FINAL 的作用。
交换 Boolean.TRUE 和 Boolean.FALSE 的值,为什么能够改变原代码的运行逻辑呢?我们看到,recitePoems 方法的形参是 boolean 的包装类型 Boolean,直接将 true 和 false 作为实参调用它时,将会发生自动装箱操作。而自动装箱操作是通过调用 Boolean.valueOf() 方法完成的,我们看看这个方法的源码:
1 | /** |
可以看到,Boolean.valueOf() 方法直接使用了 Boolean.TRUE 和 Boolean.FALSE 两个常量。这就是我们能做到如此“是非颠倒”的原因。
所以说,一个程序的命运啊,当然要靠自我的奋斗,但也要考虑历史的进程。你绝对不会知道,好好的一个 true,怎么就变成 false 了呢。
这篇文章讲了这么久也没别的,大概三件事:一个,去掉 Boolean.TRUE 和 Boolean.FALSE 的 final 修饰符;第二个,交换了它们的值;第三个,就是基本类型自动装箱的细节;如果说还有一点成绩,那就是在公司每个项目的 main 方法上调用了一下 doSomeMagic 方法,这对于被炒鱿鱼的命运有很大的关系。
很惭愧,就做了一点微小的工作,谢谢大家。
]]>英文原文是Matt Warren发表在MSDN Blogs的系列文章之一,英文渣渣,翻译不供参考,请直接看原文。
现在写一篇新的文章的时间变得越来越长,似乎已经成了一个趋势了。要怪就怪电视编剧罢工吧,嗯。
我之前说过要把我们的查询翻译器不断累积下来的不必要的嵌套select表达式给清理掉。对于人类的大脑来说,简化一条SQL是一件很简单的事情。但是,对于计算机程序而言,保留这些无用的嵌套查询却更加容易,毕竟它们的语义是一样的。再者,我们希望少写一点代码的心情也无可厚非。
我们很容易就能从一条带有where子句的简单的查询中看出问题所在。
1 | from c in db.Customers |
这条普通的查询将翻译为下面的SQL:
1 | SELECT t1.Country, t1.CustomerID, t1.ContactName, t1.Phone, t1.City |
为什么会有一个多余的SELECT?如果你理解了我们的翻译器的工作方式,并且知道这条LINQ查询的本质是什么的话,很容易就能知道答案。
这条LINQ查询的方法调用语法如下:
1 | db.Customers.Where(c => c.Country == "UK").Select(c => c); |
这里面有两个LINQ查询操作符,Where()和Select()。我们在QueryBinder类中的翻译引擎将这两个方法调用翻译为两个独立的SelectExpression。
理想情况下,SQL查询应该如下所示:
1 | SELECT t0.Country, t0.CustomerID, t0.ContactName, t0.Phone, t0.City |
然而,这只是很简单的情况,随着操作符的增加,所生成的SQL会越来越槽糕。你觉得翻译器能够聪明到将多个where子句合并到一起吗?我确实没有添加任何代码。如果语言编译器能够帮我们完成这个工作就再好不过了,但是如果额外的where子句是在原查询已经创建完成之后添加到其中的又会如何呢?
1 | var query = |
这样翻译出来的SQL就变成了一个三层的庞然大物,可它又不能吃,要那么大干嘛。
1 | SELECT t2.CustomerID, t2.ContactName, t2.Phone, t2.City, t2.Country |
不仅如此,我只是添加了一个小小的投影,翻译器都会额外创建一个嵌套查询。
1 | var query = |
翻译出来的SQL如下:
1 | SELECT t2.CustomerID |
为什么内层的查询要把外层从来没有用到过的数据给select出来?但愿数据库的优化做得够好,不要传输那些用不上或者没有必要返回到客户端的数据。但是,如果我们的查询翻译器能够自己消除这些重复的嵌套,将其转换为像一个真正的人类写出来的简单的形式的话,不是更好吗?这样,我们就可以写像下面一样复杂的查询了:
1 | var query = from c in db.Customers |
我都不敢给你看这条查询会生成什么样的SQL了,因为我担心它会吓得你把电脑都关了。
接下来我就要告诉你我是如何挽起袖子写了些代码来拯救你的。其实也不是特别难。我原以为我们的代码会因为表达式树的不可变的特性而变得越来越复杂,因为order-by重写器似乎会很复杂,需要对表达式树进行的转换也越来越有趣。然而,我很惊喜地发现,我们清理多余的嵌套查询的逻辑实现起来却特别的简洁。
]]>英文原文是Matt Warren发表在MSDN Blogs的系列文章之一,英文渣渣,翻译不供参考,请直接看原文。
距离上篇文章,又已经过了几个星期。我感觉大家可能已经迫不及待想要看到下篇文章了。你们的提供程序本来应该已经完成,可以拿到外面去惊艳众人,但是现在却放在角落里吃灰。
今天的话题是翻译order-by子句。幸运的是,进行排序操作的方式只有一种,那就是LINQ的排序操作符。但坏消息是,有四种不同的操作符。
使用查询的语法来写一条排序的查询是很简单的,只需一个子句就好。
1 | var query = from c in db.Customers |
但是,将上面的查询转换为方法调用的形式的话,所涉及到的就不止是一个LINQ操作符了。
1 | var query = db.Customers.OrderBy(c => c.Country).ThenBy(c => c.City); |
事实上,对于每个特定的排序表达式,都有它对应的排序操作符。因此LINQ提供程序在翻译SQL的时候,就需要将这些独立的操作符转换到一个单独的子句中。翻译这个的代码会比翻译之前的那些操作符的代码复杂一点,主要是因为需要先将这些独立的操作符全部找出来,才能对它们进行操作。之前的那些操作符可以简单地在前一个查询的外面套一个新的select,它们要考虑的只是当前操作符的那些参数。而排序不是,它还要考虑到其他的操作符。
首先,我们需要一种用来表示order-by子句的方式。最简单的方式是在已有的SelectExpression中加上一个描述排序的属性。但是,因为每个排序表达式都有一个排序方向,升序或降序,所以我需要把这些方向也保存下来。
所以,我添加了下面的新的定义:
1 | internal enum OrderType { |
这个新的类型OrderExpression并不是一个真的Expression节点,因为我并不打算把它用在表达式树的任何位置,它只作为SelectExpression定义的一部分出现。因此SelectExpression也有一点小变化。
1 | internal class SelectExpression : Expression { |
当然,DbExpressionVisitor也需要一点小变化,以支持排序的功能。
1 | internal class DbExpressionVisitor : ExpressionVisitor { |
另外,我们还必须修改一下所有创建SelectExpression的地方,但这相对比较容易。
将order-by子句转换为文本也不是那么难。
1 | internal class QueryFormatter : DbExpressionVisitor { |
麻烦的地方是QueryBinder,我们需要从这些方法调用表达式中读取需要的信息创建一个排序子句。我决定构造一个排序表达式的列表,然后把它们全部放到同一个SelectExpression中。因为ThenBy和ThenByDescending操作符必须跟在其他排序操作符后面,因此可以很容易自上而下遍历表达式树,将每个排序表达式添加到一个集合里面,直到访问到最后一个order-by子句(一个OrderBy或OrderByDescending操作符)为止。
1 | internal class QueryBinder : ExpressionVisitor { |
当BindThenBy方法(处理ThenBy和ThenByDescending)被调用时,我仅仅将此调用的参数追加的一个保存了then-by信息的列表中。我复用了OrderExpression类,用它来保存then-by信息,因为它们的结构是一样的。然后,当BindOrderBy方法被调用时,我们就得到了所有的排序表达式,构建一个单独的SelectExpression。注意,在我绑定then-by的时候,我逆序遍历了这个集合,因为then-by信息是从后往前添加进集合里的。
现在,一切都准备就绪了。
用下面这个查询测试一下吧:
1 | var query = from c in db.Customers |
它会被翻译为如下的SQL:
1 | SELECT t1.CustomerID, t1.ContactName, t1.Phone, t1.City, t1.Country |
哈哈,正如我所料。
不幸的是,事情还没有完。也许你知道我接下来要说什么,也许你会想,这家伙可能只是沉浸在其中不能自拔吧,这篇文章还有那么长。他不可能还没有完成,一定是搞错了,他一定是想骗我。搞得好像这是一个大难题一样,啊!我讨厌难题。
没错,上面的解决方案确实有问题。在这个例子中,排序似乎没有什么问题,翻译器翻译这个查询,服务器接收并运行它,返回一个排序好的结果。问题在其他潜在的地方。事实上,LINQ与SQL比起来,其排序的语法更为灵活自由。目前的情况是,只要稍微改一改上面的查询,翻译器就会生成一条无法在数据库上运行的非法的SQL。
LINQ允许你在任何你喜欢的地方放置排序表达式,而SQL的限制却比较严格。虽然会有一些特例,但是大部分情况下,我们都只能在最外层的select查询中写唯一的一个order-by子句。就比如我上面的例子,假如我将order-by子句的位置换到前面会怎么样?假如我在排序之后还使用了其他LINQ操作符的话会怎么样?
就好比下面这个查询。
1 | var query = from c in db.Customers |
它和之前的查询十分相似,只不过在orderby后面多了一个where子句。在SQL里面是不能这么写的。就算能这么写,我们的提供程序又会生成什么样的SQL呢?
1 | SELECT t2.City, t2.Country, t2.CustomerID, t2.ContactName, t2.Phone |
啊,这绝对是运行不了的。且不说这条SQL的文本长度可能会超出限制,单说order-by子句,它属于嵌套的子查询,这样子排序是不会发生的。至少,我们要做到,当用户这样子写的时候,不能抛出一个异常吧。
现在甚至在查询里面加一个简单的投影操作都会引发异常。
1 | var query = from c in db.Customers |
翻译上面的查询会出现同样的问题。
1 | SELECT t2.Country, t2.City, t2.ContactName |
很明显,还有做一些额外的工作才能避免异常。问题是,什么工作?
(此处应有沉默)
当然,我早已有了你们期待的解决方案。我必须重建一下这颗查询树,使其遵守SQL排序的语法规则。这意味着将排序表达式从它们不该存在的地方提出来,放到它们应该在的地方去。
这件事做起来并不是那么容易。基于LINQ表达式节点的查询树是不可变的,这意味着我们不能修改它。但这并不是最难的地方,因为我们的访问器能够自动识别变化并且为我们创建一颗新的不可变的树。最难的地方是确保所有的表别名都能够正确匹配,并且处理好order-by子句引用到已经不存在的列的情况。
似乎重头戏现在也还没开始。
那么要如何实现呢?我另外写了一个访问器类,它负责移动树中的order-by子句。虽然我已经尽可能地简化它的代码,但是最终还是很复杂。其实我可以将这些重建树的逻辑集成到QueryBinder类中去的,但是这样会给已有的代码徒增许多复杂度。因此将这些逻辑提取出来会更好,这样就不会对其他代码造成影响。
看看代码吧。
1 | /// <summary> |
代码好多:-)
主要的访问算法的工作方式如下。访问器自底向上遍历表达式树,它维护了一个增长的order-by表达式的集合。它与QueryBinder类刚好是相反的,QueryBinder自顶向下遍历表达式树,将then-by表达式添加到集合中。如果外层查询和内层查询都有order-by表达式的话,它们两个的表达式都不会丢失。外层查询的order-by表达式会放在内层查询的order-by表达式的前面。VisitSelect方法中调用了PrependOrdering方法,将当前order-by表达式添加到增长的列表的头部。
接下来我判断当前select节点是不是最外层的select节点,如果是,则它可以拥有order-by表达式,如果不是则不能拥有。如果我支持了TSQL的TOP子句的话,这个判断就有意思了。另外,我还要判断这个select节点是否可以向外层传递排序信息,如果它是内层节点的话,则可以。当然,如果我支持DISTINCT关键字的话,这里还会有更多的工作要做,原因在待会介绍RebindOrdering方法的时候就会明了。
当确定某个节点必须将它的order-by表达式传递到其外层节点时,这些order-by表达式必须要修改,以使其引用当前select节点的表别名,因为这些表达式原本引用的是内层查询的表别名。另外,如果order-by表达式中引用到了一些不存在于当前select节点的列投影中的列的话,我们还需要将这些列添加到投影中去,以便在外层查询中还能访问到它们。这整个过程称为重新绑定,这些逻辑都已经封装在RebindOrdering方法中。
现在回到之前说的那个问题,如果一个select节点使用了DISTINCT关键字,那么往投影中添加order-by表达式中引用到的列就会出错了。这些新添加的列会影响到distinct操作的结果。现在倒是不用担心这个问题,因为我们根本就不支持distinct,但是我们以后会支持,所以最好要提前考虑到这点。这就是LINQ to SQL在distinct或union操作中不支持排序的真正原因。
把前面提到的所有东西都加到代码里来,我们只需要修改一下DBQueryProvider类,让它调用新添加的访问器即可。
1 | public class DbQueryProvider : QueryProvider { |
现在,执行下面这个不算太复杂的查询。
1 | var query = from c in db.Customers |
翻译后得到如下SQL:
1 | SELECT t3.City, t3.ContactName |
这可比之前生成的SQL好多了。
执行完成后,得到如下输出:
1 | { City = Cowes, ContactName = Helen Bennett } |
好了,这就是排序的实现,至少也算是一个好的开始。
当然,如果我们能将那些不必要的子查询去掉的话就更好了。也许下次吧:-)
]]>英文原文是Matt Warren发表在MSDN Blogs的系列文章之一,英文渣渣,翻译不供参考,请直接看原文。
从上篇文章到现在,已经有好几个星期没有更新了。希望在这段时间里面你们也有用自己的时间来探索如何构建自己的提供程序。我也一直在关注别人的各种各样的“LINQ to XXX”的项目,感觉都很不错。今天我将向你们介绍如何在我的提供程序中添加连接查询的功能,比起只支持select和where来,支持join将能提供更多有趣的用法。
在LINQ中有许多种不同的连接查询的写法。在C♯或者VB中,如果写了多个from子句,将会产生笛卡尔积的结果,但如果把一个子句的键和另一个子句的键匹配起来,所得到的就是一个连接查询。
1 | var query = from c in db.Customers |
当然,也可以使用显式的join子句。
1 | var query = from c in db.Customers |
这两个查询会得到相同的结果,那么为什么做同一件事会有两种不同的方式呢?
原因有点复杂,但我会尝试解释清楚。显式连接要求我们指定两个匹配的键表达式,用数据库的术语来说,就是等值连接。而嵌套from子句具有更大的灵活性。显式连接具有如此限制的原因是,通过这种限制,使得LINQ to Objects的实现不必去分析和重写查询,进而使执行更加高效。好消息是,在数据库中用到的连接几乎都是等值连接。
并且,因为有了限制,所以显式查询的表达能力会比较低,因此实现起来会更加简单。在这篇文章里,两种连接方式我都会实现,但我会先完成显式连接,因为它的坑比较少。
Queryable.Join方法的定义如下:
1 | public static IQueryable<TResult> Join<TOuter,TInner,TKey,TResult>( |
好多参数好多泛型!但是实际上理解起来也不是那么难。inner和outer是两个输入序列(join关键字两边的序列);每个输入序列都有一个键选择器(on子句中equals关键字两边的表达式);最后是一个产生连接查询的结果的表达式。最后这个resultSelector可能会使人迷惑,因为在C♯或VB的语法中看起来好像没有这个东西。但实际上是有的,在上面的例子中,它就是select表达式。在其他地方,它也有可能是一个编译器生成的投影,用来将数据传递到下一个查询操作中。
没关系,直接开干吧。实际上,我早已万事俱备,只欠东风了。这个东风就是表示连接的新的节点。
现在在代码中加上这个节点。
1 | internal enum DbExpressionType { |
我在枚举中加上了新的节点类型“Join”,然后实现一个JoinExpression类。
1 | internal enum JoinType { |
我还定义了一个JoinType的枚举,里面是我待会要用到的连接类型。CrossApply是SQL Server中独有的连接类型。现在先忽略它,在实现等值连接的使用用不到它。实际上,现在只需要InnerJoin,另外两个在后面才会用到。我说过,显式连接是比较简单的。
那么外连接呢?这个我们会在后面的文章中讨论:-)
现在多了个JoinExpression,所以DbExpressionVisitor得改一改。
1 | internal class DbExpressionVisitor : ExpressionVisitor { |
还挺不错的。现在是改改QueryFormatter,以支持新添加的节点。
1 | internal class QueryFormatter : DbExpressionVisitor { |
现在的想法是,JoinExpression与其他查询源表达式(比如SelectExpression和TableExpression)在表达式树中是处于同一级别的,能出现它们的地方就能出现JoinExpression。因此我修改了VisitSource方法以使它支持连接,还增加了一个新的方法VisitJoin。
当然,如果不能将调用了Queryable.Join方法的表达式节点转换为我的JoinExpression的话,前面的工作就等于白费了。我需要在QueryBinder中添加一个方法,就像BindSelect和BindWhere方法一样。这就是实现显式连接的主要代码,因为有了之前实现其他操作符的时候写的代码的支持,所以实现显式连接显得特别简单。
1 | internal class QueryBinder : ExpressionVisitor { |
一眼看过去,BindJoin方法里面的实现与其他两个操作符的实现几乎是一样的。我首先将传入的两个源转换为两个不同的源的投影。我将这两个源的投影的投影器保存在全局的map对象中,在待会翻译两个键表达式的时候用来替换掉参数引用。最后在对结果表达式作同样的操作,不同的是结果表达式可以同时访问到两个源投影,而不仅仅是一个。
当所有的输入表达式都翻译完成之后,我就拥有了表示这个连接查询的足够的信息,因此已经可以创建JoinExpression了。然后再创建一个SelectExpression,将其包装起来,这里就需要调用ProjectColumns方法以产生一个数据列的列表以供SelectExpression使用。注意,现在ProjectColumns方法有一点小变化,它现在允许指定多个已存在的表别名。这点很重要,因为在连接操作里面,结果表达式很有可能会引用两个表别名。
搞定,所有东西都做完了。应该可以支持显式连接了。
试一试吧。
1 | var query = from c in db.Customers |
执行上面的代码,产生如下输出:
1 | SELECT t2.ContactName, t4.OrderDate |
接下来就是难啃的骨头了:-)
如果你写过SQL的话,你可能会感到很不解,为什么我说嵌套“from”子句实现起来会比较困难。毕竟在SQL里面它与显式连接仅仅是CROSS JOIN和INNER JOIN的区别而已。在LINQ这种倾向于非SQL的语言来说,CROSS JOIN其实并不是连接,而是交叉乘积。为了将它变成连接,需要在where子句中放一个连接条件来进行真正的连接操作。所以,在SQL的层面上,唯一的区别就是,CROSS JOIN将连接条件放在WHERE子句中,而INNER JOIN将连接条件放在ON子句中。好像也没什么问题。
不,还有很多问题。问题不在SQL上,大部分都在SQL以外的地方。如你所见,LINQ中的嵌套from与CROSS JOIN并不一样。有时候是一样的,但不全是。
在这个时候问题才会出现。一个连接使用连接条件将两个完全独立的子查询连接起来,这时只有连接条件才能够同时访问到两个子查询中的列。但是LINQ中的嵌套from就很不一样了,在LINQ中,内层的源表达式是可以访问到外层的源的。将它们想象为一个嵌套的foreach循环,内层循环可以访问到外层循环中的变量。
问题就在于要如何合适地翻译这种内层from子句中引用了外层的变量的查询。
如果你的查询是这样写的,那么没有问题:
1 | var query = from c in db.Customers |
将其转换为等价的方法调用的形式如下:
1 | var query = db.Customers |
这个SelectMany方法中的集合表达式db.Orders没有任何对“c”的引用。这样翻译成SQL是很容易的,因为我们可以简单地把db.Customers和db.Orders放在连接的两端。
然而,稍微换个写法的话,就像这样:
1 | var query = from c in db.Customers |
现在可遇到大麻烦了。将上面的查询转换为等价的方法调用的形式如下:
1 | var query = db.Customers |
现在,连接条件是作为SelectMany的集合表达式的一部分存在的,因此它引用了“c”。现在,翻译就再也不能简单地把两个源表达式放在SQL的连接两边了,无论是交叉连接还是内连接。
那么我要如何解决这个问题呢?我没有解决,真的,我用的是一种简单粗暴的方式。我打算利用一下微软的SQL。Microsoft SQL2005提供了一个新的连接操作符,CROSS APPLY,它正好与现在的这个情况具有相同的语义,这实在是一个让人高兴的巧合。CROSS APPLY右侧的表达式可以引用左侧表达式中的列。这就是我为什么要在定义JoinType枚举的时候加入CrossApply的原因。
大部分的LINQ to SQL引擎都会尽可能地将CROSS APPLY转换成CROSS JOIN。如果不这样做的话,LINQ to SQL在SQL2000里面可能就不能正常执行。当然,即使这样,还是有一些查询是无法转换成CROSS JOIN的。为了在这个示例提供程序里面添加这个特性,我还要做许多工作。虽然并不是很情愿,但是我也没有那么绝情,所以还是做了一点,算是抛砖引玉吧。我会处理一些简单的情况,将其转换成CROSS JOIN。
所以让我们看看代码吧。
1 | internal class QueryBinder : ExpressionVisitor { |
第一件值得注意的事情是,SelectMany方法有两种不同的形式。第一种形式以一个source表达式和一个collectionSelector表达式为参数。collectionSelector产生一系列具有相同成员类型的序列,SelectMany方法仅仅是将这些序列合并成一个大的序列。第二种形式多了一个resultSelector,它允许你从连接的两个序列中投影出自己的结果。我实现的BindSelectMany方法可以指定resultSelector参数,也可以不指定。
注意,在这个函数的第四行,我判断了应该使用哪种连接类型来表示这个SelectMany调用。如果我能确定collectionSelector只是一个简单的表查询的话,我就能够得知它没有引用任何外层查询变量(collectionSelector lambda表达式的参数)。这样我就可以安全地选择CROSS JOIN而不是CROSS APPLY。如果想做得更复杂一点的话可以写一个访问器来判断collectionSelector中到底有没有引用。也许下次我会写的,我有种预感,可能到时候我会因为其他原因而不得不这么做。但是这里只是一个简单的示例。
总而言之,这里的代码和BindJoin方法或其他方法里面的很不一样。我必须要处理resultSelector没有指定的情况。在这种情况下,我简单地重用collectionProjection来充当最终的投影。
让我们测试一下新的代码吧。
1 | var query = from c in db.Customers |
执行上面的代码,产生如下结果:
1 | SELECT t6.ContactName, t6.OrderDate |
哎呀,这个查询执行起来好像太慢了。我猜这是因为我盲目地添加新的嵌套查询而导致的。也许以后我会找个方法来去掉里面不必要的子查询:-)
当然,如果将这个查询的写法改成这种无法通过简单检查的形式的话,得到的结果就是CROSS APPLY。
1 | var query = db.Customers |
上面的代码产生如下结果:
1 | SELECT t2.ContactName, t5.OrderDate |
正如我所料!
现在我的提供程序已经支持Join和SelectMany调用了,我仿佛听到了你们的欢呼声。这个提供程序的功能已经很多了,但是还是有一些明显的坑没有填,还是有一些操作符没有实现,应该给我发工资才对得起我的辛勤付出啊。
英文原文是Matt Warren发表在MSDN Blogs的系列文章之一,英文渣渣,翻译不供参考,请直接看原文。
你又以为这个系列已经完成,所以我已经转移到其他阵地上去了吗?因为Select操作工作得非常好,所以你以为前面所讲的就是你构建自己的IQueryable提供程序所需要了解的所有内容了吗?哈!还有很多需要学习的呢,而且,Select操作还是有些漏洞。
有漏洞?怎么可能?我把你当成从来不会出错的微软大神,但是你却说你给我的是劣质的代码?我把已经把代码复制粘贴到产品里,老板已经说了下周一就启动!你怎么能这么做?(喘气)
放心啦,不是什么严重的漏洞,只是一点小小的缺陷而已。
回想一下,在上篇文章中,我建了四种表达式节点,Table,Column,Select和Projection,它们工作十分良好,不是吗?有漏洞的地方是我没有考虑到所有可以写查询表达式的地方。我考虑到的只是最明显的Projection节点出现在查询表达式树顶的情况。毕竟,因为我只支持Select和Where,所以最后一个操作必定是这两者之一。我的代码就是这样假设的。
这不是问题所在。
问题是Projection节点也有可能出现在选择器表达式里面,例如,看下面的查询。
1 | var query = from c in db.Customers |
我在选择器表达式里面写了一个嵌套查询,这与我们之前写的表格式的查询非常不一样。现在我希望我们的提供程序创建嵌套的对象,每个对象都有一个名字和一个订单的集合。这样的查询要怎么实现?SQL甚至都做不到这一点。即使我彻底不支持这种写法,万一有人真的这么写又会发生什么呢?
额,抛出了一个异常,然而并不是我预想的那个异常,看来代码中的bug比我预想的要多。因为这个可爱的查询在选择器表达式中有一个ProjectionExpression,所以我期望在编译投影器函数的时候会抛出一个异常。我之前说过添加自己的表达式节点是没问题的对吧?理由是只有我们才能看到这些节点,哈,看来是我错了。(实际上抛出来的异常是因为我在构建Projection节点的时候弄错了它们的类型而导致的,这个以后再修复。)
现在假设我已经修复了这个类型异常,我要如何处理这个嵌套的Projection节点呢?我可以捕捉这个异常,然后抛出一个自己的异常,加个道歉声明说不支持嵌套查询。但是这样的话我就不是一个好的LINQ开发者,也享受不到解决这个问题的乐趣了。
所以,让我们继续前进吧。
我希望能够将嵌套的ProjectionExpression转换为嵌套的查询。SQL实际上也做不到这一点,所以我必须在自己的代码做一些事情以达到这种效果。然而,在这里我并不打算做成一个超级完善的解决方案,我只要能取回数据就够了。
因为投影器函数必须要转换为可执行的代码,所以我得将里面的ProjectionExpression节点给替换成从某个地方获取数据以构建Orders集合的代码。数据不可能来自现有的DataReader,因为它只能保存表格式的结果,因此应该来自另一个DataReader。我真正要做的就是将ProjectionExpression转换成执行的时候返回这个集合的一个函数。
我们好像在之前见过类似的东西?
思考中。。。
对,这或多或少就是我们的提供程序所做的事情。呼,事情好像有点难。提供程序早已通过Execute方法将表达式树转换成了结果序列。我想我已经完成一半了。
所以我需要在之前的ProjectionRow类中添加一个执行嵌套查询的函数,它回调提供程序以执行真正的工作。
下面是ProjectionRow和ProjectionBuilder的代码。
1 | public abstract class ProjectionRow { |
就像在遇到ColumnExpression时插入GetValue方法调用一样,在遇到ProjectionExpression时也要插入ExecuteSubQuery方法调用。
在base.VisitProjection调用返回之后,投影器表达式中的相应的ColumnExpression已经被替换掉了。我决定将投影器表达式和指向ProjectionRow的参数绑定在一起,刚好有一个类可以做这件事,LambdaExpression,因此我将它作为ExecuteSubQuery方法的参数类型。
注意我是将subQuery作为一个ConstantExpression传进去的,这是为了骗过LambdaExpression.Compile方法,使之注意不到我们自己增加的节点。总之我不想让我们自己增加的节点被编译。
下一个要看的是修改过的ProjectionReader类,当然,Enumerator现在也实现了ExecuteSubQuery方法。
1 | internal class ProjectionReader<T> : IEnumerable<T>, IEnumerable { |
我在创建ProjectionReader时将provider的实例传了进去,它在下面的ExecuteSubQuery中执行子查询时会用到。
看ExecuteSubQuery方法,hey,那个Replacer.Replace是个什么鬼?
我还没有告诉你这个类是什么,待会会给出它的代码,我们先来解释一下ExecuteSubQuery方法干了什么。我们获得了一个LambdaExpression类型的参数,它的body是内查询原始的ProjectionExpression,parameter是指向当前ProjectionRow的引用。虽然一切都是极好的,但问题是我不能通过回调provider来执行这个表达式,因为所有引用了外层查询(想想Where子句里面的连接条件)的ColumnExpression现在都被替换成了GetValue表达式。
没错,我在内层查询里面引用了外层查询,我不能让这些GetValue继续留在表达式中,因为这样的话子查询在执行的时候会尝试去访问不存在的列,好囧。
思考中。。。
啊哈,想到了!这些GetValue方法要获取的数据其实早就可用,并且近在咫尺,这些数据就在DataReader当前行里面。所以我想做的就是以某种方式将这些表达式的值马上“计算”出来,强制子表达式调用GetValue方法。要是已经有代码来做这件事那就太完美了。
等等,这不正是Evaluator.PartialEval方法的工作吗?当然,但是在这里并不管用。为什么?因为这些表达式引用了ProjectionRow参数,而ParameterExpression又是让Evaluator类不对其进行计算的标志。如果我能去掉这些参数引用,将其替换为指向当前ProjectionRow实例的常量表达式的话,就可以使用Evaluator.PartialEval方法将它们替换为实际的值了。这样一切都好办了。
怎么做呢?我需要一个工具,它查找表达式树中的节点,并将其替换为另一个节点。
下面是Replacer类,它简单地遍历一棵树,寻找一个节点的引用,将其替换为另一个不同节点的引用。
1 | internal class Replacer : DbExpressionVisitor { |
漂亮,我都被自己的机智吓到了。
好了,现在我已经可以将那些讨厌的ProjectionRow参数的引用替换成实际的对象,这就是ExecuteSubQuery方法的第一行所做的事情。然而这仅花了几十行英文就解释清楚了:-)
如我所愿,第二行调用了Execute.PartialEval方法。下一行紧接着又调用了provider来执行子查询!撒花!然后我将结果放到了一个List对象中,最后我有可能还要再将它转成IQueryable。我知道这很奇怪,但是这个原生查询中Orders属性的类型就是IQueryable<Order>,这就是IQueryable查询操作符的工作方式,所以C♯创造了匿名类型以充当成员类型。如果我尝试直接返回list的话,将结果组合到一起的投影器就会报错。幸运的是,已经有了将IEnumerable转换成IQueryable的方法,Queryable.AsQueryable。
哇!这些组件就好像被精妙设计出来的一样,能够完美地协同工作了。
大揭秘:我小小作了个弊。我改了Evaluator类,使它能够识别我自己添加的表达式类型。我知道,我知道,我说过其他人没必要知道它们的存在,但是Evaluator也是我自己的代码,所以我觉得这样并没有问题。我在附件的zip文件中附带了这个小小的修改,在这里我只放出有大修改的代码,那点小修改就不放出来了。
我还得写一个新的CanEvaluateLocally规则以供Evaluator类使用,我得确保它不会将我自己添加的那些节点视为可计算的。
所以让我们来看看DbQueryProvider有什么变化吧。
1 | public class DbQueryProvider : QueryProvider { |
唯一有变化的是Translate方法。当传进来的参数是ProjectionExpression时,就不再进行将表达式转换成ProjectionExpression的操作,而是直接跳到构建SQL命令和投影器的步骤。
差点忘记,我还添加了类似LINQ to SQL的日志的特性,它能帮助我们看清背后的执行过程。我的上下文类里面也加了Log属性。
1 | public class Northwind { |
现在,让我们试试这个新的魔法般的特性把。
1 | string city = "London"; |
执行上面的代码,产生如下输出:
1 | Thomas Hardy |
下面是查询的执行过程(我用了新的Log属性捕捉到的):
1 | SELECT t2.ContactName, t2.CustomerID |
虽然让内层查询执行许多次不是很理想,但是总比直接抛出一个异常要好。
现在,Select操作已经最终完成了,它现在已经可以支持任意的投影了。也许吧:-)
]]>英文原文是Matt Warren发表在MSDN Blogs的系列文章之一,英文渣渣,翻译不供参考,请直接看原文。
在前面四篇文章里面,我构建了一个LINQ IQueryable提供程序,它可将Queryable.Where和Queryable.Select两个标准查询操作符翻译成SQL,并通过ADO送到数据库中去执行。虽然已经做得很不错,但是这个提供程序还是有一些漏洞,而且我还没有提到其他的查询操作,比如OrderBy和Join等等。如果认为用户写出的查询都像我的demo一样这么理想化的话,你可能就会掉进大坑里去。
我确实可以写出一个简单的带有where和select的运行良好的查询,就算这个查询再复杂也没关系。
1 | var query = db.Customers.Where(c => c.City == city) |
然而,只要将Where和Select的顺序换一下就坑爹了。
1 | var query = db.Customers.Select(c => new { |
这个风骚的小查询生成了一条错误的SQL。
1 | SELECT * FROM (SELECT ContactName, City FROM (SELECT * FROM Customers) AS T) AS T WHERE (Location = 'London') |
在执行的时候也会抛出异常,“Invalid column name ‘Location’”。似乎我之前直接将成员访问当成数据库列引用的太过简单的做法不太行得通。我天真地假设子树里面唯一的成员访问会与Select子句中的列的名字相匹配,然而实际上并不是。所以,现在要么改一改Select子句中的列名,使之与成员的名字一致,要么想个其它的方法来解决这个问题。
我认为两种方法都是可以的,但是,考虑一个复杂一点的情况,不仅仅是将列重命名,如果选择表达式还生成了嵌套的对象,这样的话对成员的引用很可能就是一个“多点”的嵌套操作。
1 | var query = db.Customers.Select(c => new { |
现在我要怎么翻译这个查询呢?已有的代码甚至根本就不能理解这个中间对象Location是个什么东西。幸运的是我早就知道应该怎么做了,只不过要对代码做出比较大的改动。我们需要重新审视一下提供程序仅仅只是将查询表达式翻译为文本的思路了。我们应该将查询表达式翻译为SQL,而文本只是SQL的一种表现形式,而且它还不方便我们对其施加编程逻辑。当然我们最终需要的还是文本,但如果我们能先把SQL表示为一个抽象,那么就能进行更复杂的翻译。
当然,最方便我们操作的数据结构是SQL语义树。所以,理论上我应该定义一个完整的独立的SQL语义树,将LINQ查询表达式翻译为一颗SQL语义树而不是文本,但是这样做的工作量太大了。幸运的是这个假想的SQL树的定义与LINQ表达式树的定义有很大的交集,所以我们可以偷下懒,简单地将LINQ表达式树当成SQL树来使用。为了这么做,我要添加一些新的表达式节点类型,其他的LINQ API不识别这些类型也没关系,因为这只是给我们自己使用的。
1 | internal enum DbExpressionType { |
我只需要在LINQ表达式树中加上SQL Select查询的概念,Select查询产生一列或多列、一个对列的引用、一个对表的引用、和一个将列引用重新组装为对象的投影器。
我继续定义了一个自己的枚举类型DbExpressionType,它“扩展”了基本的枚举类型ExpressionType,选了一个足够大的起始值以免与其他的定义冲突。如果枚举类型可以继承的话我会直接继承ExpressionType的,但是机智如我,就算不能继承也没有关系。
每个新的表达式节点都遵循LINQ表达式的所有模式,比如不可变等等,只不过它们现在表示的是SQL的概念,而不是CLR的概念。注意SelectExpression包含了一个列的集合,一个from和一个where表达式,它们对应于一条合法的SQL所具有的各种子句。
ProjectionExpression描述了如何从SelectExpression的列中构造出结果。仔细想想就知道,它和Part IV里面为ProjectionReader构造委托的投影器表达式几乎是一样的。只不过现在它的作用不仅仅是组装此DataReader中读出来的数据,它还表示了SQL查询中的投影操作。
有了新的节点类型之后,当然就要有新的访问器。DbExpressionVisitor继承了ExpressionVisitor,添加了对新的节点类型的基本的访问模式。
1 | internal class DbExpressionVisitor : ExpressionVisitor { |
我现在真的觉得自己越来越屌了!
下面就是QueryTranslator闪亮登场的时候了。不再是整个将表达式树翻译成字符串的翻译器,而是处理不同任务的独立的模块,一个模块解释方法(比如Queryable.Select)的含义、绑定表达式树,另一个将得到的树转换为SQL文本。希望通过构造这个LINQ/SQL混合的的树能够解决这个漏洞。
下面是QueryBinder类的代码。
1 | internal class QueryBinder : ExpressionVisitor { |
要注意这里的代码可比以前的QueryTranslator复杂多了。对Where和Select方法的翻译被分发到了两个独立的方法里面。它们不再产生文本,取而代之的是ProjectionExpression和SelectExpression的实例。ColumnProjector似乎做了一些更复杂的事情,我还没有放出它的代码,但是它也有很大的变化。这里还有些获得表和列的信息的帮助方法,其具体的实现要依靠一个完整的映射系统,留待以后解决,现在简单地使用类名和成员名。
GetTableProjection是一个关键的方法,它用SelectExpression和ProjectExpression组装了一个取出表中所有数据的默认查询。这里不再使用"SELECT *",默认的表投影是为域对象里面的所有成员一一赋值的MemberInitExpression。
另一个值得注意的变化是VisitMemberAccess方法。我不再只考虑参数节点的简单成员访问,还尝试解析成员访问的含义,返回这个成员翻译出来的子表达式。
这是具体的工作流程。当通过GetTableProjection方法将“表”常量翻译为表投影时,结果里包含了一个投影器表达式,它描述了如何通过表中的列来创建对象。当翻译到Select或Where方法时,往map中添加了一个从LambdaExpression的参数表达式到“上一次”查询的投影器的映射。对于第一个Select或Where的调用,这个投影器就是表投影中的投影器。这样,待会在VisitParameter方法中访问这个参数表达式时,就可直接将其替换为上一个投影器表达式。这样是可行的,因为节点是不可变的,因此可以在树上多次包含某棵子树。最后,在翻译成员访问的时候,参数表达式早已被替换成了语义等价的投影器表达式。这个投影器表达式有可能是new或者member-init节点,所以我只需在它上面找出能替换掉此成员访问节点的子表达式即可。通常,都能找到一个在表投影中定义的ColumnExpression。但是如果上次Select操作产生了嵌套对象的话,也有可能找到另一个new或者member-init表达式,这样的话,随后的成员访问操作会从这个表达式中查找子表达式,如此反复。
呼,有好多东西要消化,我自己都还没完全理解。下面是与之前完全不同的ColumnProjector类,看代码。
1 | internal sealed class ProjectedColumns { |
ColumnProjector类不再拼接Select命令的文本,也不再将选择器表达式转换为从DataReader构建对象的函数。但是其实做的事情和以前也差不多。它产生用来创建SelectExpression节点的ColumnDeclaration的list对象,将选择器表达式转换为引用了list中的这些列的投影器表达式。
那它是如何工作的呢?就现在来看,我对这个类可能有点过度设计,但是在以后这样子会比较方便。在我介绍它的工作原理之前,让我们先想想它需要干什么。
给定选择器表达式,我需要找出里面与SQL Select子句中的列声明直接相关的子表达式。这个很简单,只需要找出绑定之后树上剩余的列引用(ColumnExpression)就好了。当然,这意味着表达式“a + b”会被视为两个列引用,一个是“a”,一个是“b”,“+”操作则会留在新创建的投影器表达式里面。这样确实可行,但是能不能将整个“a + b”表达式视为一列呢?这样的话,计算的操作就会在SQL server中执行,而不是在创建结果对象期间由本地执行。如果在这个Select操作后面有一个Where操作引用到了这个表达式的话,计算操作就无论如何都必须在服务器中执行了。现在先忽略还不能翻译“+”操作的问题吧,你可以看到,找出列引用表达式、生成投影器表达式的问题,与找出可预处理的独立子树的问题是相似的。
Evaluator使用了两次遍历,第一次遍历找出所有可本地计算的节点,第二次遍历自顶向下选中第一次遍历时找出的节点,然后计算选中的“最大”子树的值。找出表达式中的列引用(ColumnExpression)与找出最大子树实际上是一个相同的问题,唯一的不同只是查找条件的差异。不过这次我不是要计算所找出的子树的值,而是要1)将子树放进新的查询的SelectExpression的列声明中,2)将子树替换为对新的查询的列的引用,从而创建一个投影器。
检查代码你会发现这里有个Evaluator类中没有的复杂性。如果列声明真的是基于更复杂的子表达式的话,我就应该给它们生成一个列别名。
好了,现在我已经创建了混合表达式树,并且已经很好地生成了投影器表达式,但我还是要生成SQL文本,否则前面的东西都白做了。所以我将QueryTranslator中生成文本的代码提了出来,创建了一个新的类QueryFormatter,它全权负责将一颗表达式树转换为文本。
1 | internal class QueryFormatter : DbExpressionVisitor { |
除了添加了输出新的SelectExpression节点的逻辑之外,我还添加了格式化的逻辑,以支持换行和缩进。现在是不是比较特别了?
当然,最后还是要以一个构造结果对象的LambdaExpression结束。我们之前是通过ColumnProjector类来获得这个lambda表达式的,但现在它的工作是生成SQL语义投影器,而不是生成创建结果对象的投影器。所以我们需要进一步的转换,我建了一个新的类ProjectionBuilder来做这件事。
1 | internal class ProjectionBuilder : DbExpressionVisitor { |
这个类简单地做了ColumnProjector之前的工作,不过得益于QueryBinder中的更好的绑定逻辑,它现在直接就知道应该将哪些节点替换为数据读取表达式。
很幸运,我们不用重写ProjectionReader,它还是像以前那样工作。我要做的是摆脱ObjectReader,因为我们现在始终都会有一个投影器表达式,在QueryBinder中每次翻译到“表”常量时都会创建一个。
现在就是将前面讲的东西都用上的最后一步了。下面是重写的DbQueryProvider的代码。
1 | public class DbQueryProvider : QueryProvider { |
它和以前有很大的不同。Translate方法包含了很多步骤,它调用新增的各种访问器,以及Execute方法也不再创建ObjectReader对象,因为现在始终都有一个投影器。
现在,给出下面的查询:
1 | var query = db.Customers.Select(c => new { |
执行成功,产生如下输出:
1 | Query: |
更好看的查询,更好看的结果,而且现在无论有多少个Select或者Where方法,无论里面的投影有多复杂它都能运行良好。
在我指出下一个漏洞之前,至少应该让你们好好消化一下。
下次见!
]]>英文原文是Matt Warren发表在MSDN Blogs的系列文章之一,英文渣渣,翻译不供参考,请直接看原文。
我是个完美主义者,我做了一个仅仅可以将Where方法翻译为SQL的LINQ提供程序,它可以执行查询并且将结果转换为对象,但我觉得还不够完美,相信你们也这么认为。你们也许想知道从一个简单的示例程序演变成一个成熟的ORM系统的所有细节。但是我并不会做到这个程度,即便如此,我还是觉得,我可以通过介绍如何实现Select操作来覆盖到一些通用的知识点,以方便你编写自己的提供程序。
与Where操作比起来,翻译Select操作可没那么容易。我现在说的不是那种从十列里面选出五列的SQL操作,而是将数据转换为任何你想要的形式的LINQ Select操作。LINQ Select操作中的选择器函数可以是你能想象到的任何转换表达式,里面可能会有对象构造器、初始化器、条件语句、二元运算符、方法调用等等。这么多东西要如何翻译为SQL,更别说还要从返回的结果里面重新构造出对象的结构?
幸运的是,我并不会真的这样做。为什么呢?因为要写的代码太多吗?实际上是因为本来已经就有代码帮我们处理了大部分的事情,所以我才不需要熬夜奋战。我不用自己写,因为用户在写查询的时候就已经把转换代码写出来了。
选择器函数就是构造结果的代码。在LINQ to Objects中,选择器函数会被真正地调用,从而产生结果,那为何在我的查询提供程序中就要不一样呢?
啊哈,先别急。当然,如果选择器函数是可执行代码而不是表达式树的话,那是最好的,即便它是可执行代码,它也只是个将对象转换为另一个对象的函数罢了。可是我并没有要转换的对象啊。我有一个DbDataReader,它带有许多字段数据,可它是拿来生成最终的对象的,我现在还没有要拿来转换的对象啊。
当然,也许你能自己想出一个好的解决方案,将前面的ObjectReader与LINQ to Objects版本的Select操作结合起来,取出所有数据,转换成另外一种形式。但是这对时间和空间都是巨大的浪费。我们不应该取出所有的数据,我们只应该取需要拿来产生结果的数据就够了。这真是个进退两难的局面。
幸运的是,问题仍然很简单。只需要将原有的选择器函数转换成我们需要的样子就可以了。我们需要什么样子的呢?我们需要它直接从DbDataReader中读取数据。好了,我们可以将这个问题中的DataReader抽象出来,提供一个GetValue方法让选择器函数获得数据。对,我知道DataReader里面已经有了一个这样的方法,但是它有个缺点,就是可能会返回DbNull。
1 | public abstract class ProjectionRow { |
所以,我们有了一个简单的抽象基类,它代表了一行数据。如果我们的选择器表达式是从这里通过调用GetValue方法来获得数据,然后接上一个Expression.Convert强转操作的话,我真的是做梦都会笑醒。
让我们看看预处理选择器表达式的代码吧。
1 | internal class ColumnProjection { |
上面的当然不是所有的代码。ColumnProjector是一个表达式访问器,它遍历表达式树,将列引用转换为调用GetValue方法获得单个数据的表达式。那GetValue方法又是通过什么来调用的呢?通过一个名为“row”的参数表达式,它的类型就是我刚刚定义的抽象类ProjectionRow。我不仅重建了一个选择器表达式,我还要把它放在一个以ProjectionRow为参数的lambda表达式的body中。这样我就能调用LambdaExpression.Compile方法将这个lambda表达式转换为委托。
注意这个表达式访问器还构造了一个SQL的select子句。通过这个类,我既可以将Query.Select中的查询表达式转换为处理查询结果的函数,又能得到SQL命令中的select子句。
让我们来看看怎么使用这个类吧,下面是修改后的QueryTranslator(仅给出相关内容)。
1 | internal class TranslateResult { |
如你所见,QueryTranslator现在处理了Select方法,它就像Where方法一样构建一条SQL SELECT语句。但是它还保存了最后一个ColumnProjection对象(调用ProjectColumns方法的结果),在TranslateResult对象中以lambda表达式的形式返回新构建的选择器表达式。
现在我们只需要一个ObjectReader类,它使用这个lambda表达式来处理数据,而不是像之前那样仅仅只是创建一个对象。
看下面的代码。
1 | internal class ProjectionReader<T> : IEnumerable<T>, IEnumerable { |
ProjectionReader类与Part II中的ObjectReader类十分相似,只是去除了使用各个字段来创建对象的逻辑,替换成了一个名为projector的委托的调用。这就是我们重建的选择器表达式编译出来的委托。
记得吗,我们重建的选择器表达式是以ProjectionRow为参数的。现在你可以看到ProjectionReader里面的Enumerator就实现了ProjectionRow。这是件好事,因为它是这里唯一一个直接访问了DbDataReader的类,并且我们在调用委托的时候还可以很方便地将this作为参数传进去就好了。
似乎所有组件都已经没问题了,现在让我们把它们组装到DbQueryProvider中去。
下面是新的provider的代码:
1 | public class DbQueryProvider : QueryProvider { |
对Translate方法的调用返回了我需要的所有东西,我只需要再调用Compile方法将lambda表达式转换为委托就可以。注意我仍然需要保留ObjectReader类,它会在查询中没有Select操作的时候用到。
现在来试试最后的结果如何吧。
1 | string city = "London"; |
执行上面的代码,输出结果如下:
1 | Query: |
看,我没有再返回所有数据了,这正是我想要的。翻译后的选择器表达式转换成了一个委托,这个委托包含了“new xxx”的匿名类型初始化器,调用了GetValue方法从DataReader中读取数据保存到返回的对象中,不需要再使用反射对每个字段赋值了。我们的查询提供程序越来越好了,你一定觉得我们应该已经完成了,这个提供程序好屌!还有什么是没做的吗?
我们还有许多的事情要做。即使有了Select,即使它真的能运行良好,这个解决方案还是有一些漏洞,要修补的话还要对代码进行大改。
幸运的是,对我来说,这才是好玩的部分,Part V中再见。
Matt.
]]>英文原文是Matt Warren发表在MSDN Blogs的系列文章之一,英文渣渣,翻译不供参考,请直接看原文。
第三部分?难道上篇文章还没有讲完吗?我不是做了一个可以翻译和执行SQL命令并且返回一个对象序列的提供程序了吗?
确实如此,但是也仅仅如此而已。我写的那个提供程序的功能实在太弱,它只支持一种查询操作符与少量比较运算符。然而,真正的查询提供程序必须要提供更多的查询操作与更复杂的交互方式。我的查询提供程序甚至还不支持将数据投影为其他形式。
你知道当查询里面引用了局部变量的时候会发生什么吗?不知道?
1 | string city = "London"; |
去试试翻译上面这句查询的时候会出现什么情况吧,我等着你的结果。
靠,抛出了一个异常,“The member ‘city’ is not supported.”,这是什么意思?我将“成员”City视为表中的一列,这个异常指的是局部变量city。但是为何局部变量也是一个“成员”呢?
让我们再看看对表达式树调用ToString()方法的结果。
1 | Console.WriteLine(query.Expression.ToString()); |
输出:
1 | SELECT * FROM Customers.Where(c => return (c.City = value(Sample.Program+<>c__DisplayClass0).city)) |
啊哈,C♯编译器生成了一个类来保存被lambda表达式引用到的局部变量,这和匿名函数中引用到外部的局部变量的时候的处理是一致的。但是这个你早就知道了对吧?不知道?
算了,我们现在来为之前的提供程序添加支持局部变量引用的功能吧。也许我们能够识别出这些编译器生成的类型中的字段引用,那么要如何确定一个编译器生成的类型呢?通过类名?如果编译器改变了它们的命名怎么办?如果另一种语言里面是另一种模式怎么办?还有,我们关注的点仅仅只有局部变量吗?如果引用了作用域范围中的成员变量呢?它们在表达式树中并不是单纯的值,它们可以是引用了成员变量所指向的实例的一个constant节点,也可以是访问某个对象的成员的MemberAccess节点。你能够仅仅通过反射就识别出constant节点所引用的成员变量并且得到它们的值吗?也许可以,但是万一编译器生成了一个更复杂的类型呢?
好吧,我要给出的是一个通用的解决方案,它转化了编译器生成的表达式树,使之更像我指出这些问题之前的样子,让人容易接受。
我真正想做的是将树上可以计算出值的子树替换成所计算出来的值。如果能做到的话,查询翻译器就只需要处理这些值就好了。谢天谢地,我已经有一个现成的ExpressionVisitor类,我可以用它实现一个简单的规则来判断哪些子树可以直接计算出值。
先看看下面的代码,我待会会解释它的工作原理。
1 | public static class Evaluator { |
Evaluator类暴露了一个静态方法PartialEval,你可以调用这个方法来计算你的表达式树中的子树,并将其替换为计算结果的constant节点。上面的代码做的事情大部分是将可以独立计算的最大子树找出来,而真正的计算过程并没有什么特别,因为子树可以通过LambdaExpression.Compile方法“编译”成委托然后执行。这些事情都是在SubtreeVisitor.Evaluate方法中发生的。
找出最大子树的过程分为两步。首先是在Nominator类中对表达式树进行自底向上的遍历,找出所有可以独立计算的子树,然后在SubtreeEvaluator类中进行自上而下的遍历,找出代表选中的子树的最高节点。
Nominator以一个函数作为参数,你可以随意指定一个方法作为判断指定节点是否可独立计算的条件。默认的判断条件是除了ExpressionType.Parameter类型以外的所有节点都可以独立计算。另外,如果子节点不可独立计算那么父节点也不可独立计算。因此,parameter类型的节点的所有上游节点都不可独立计算,它们都会保留在树上,而剩余的其他节点都会被计算出结果并且替换成constant节点。
现在我就可以在任何翻译表达式的操作之前使用上面的类对表达式进行预处理了。幸运的是,我已经把翻译操作分解到了DbQueryProvider类的Translate方法里面。
1 | public class DbQueryProvider : QueryProvider { |
现在我们再试试执行下面的代码就能得到正确的结果了:
1 | string city = "London"; |
输出:
1 | Query: |
结果正是我们想要的,我们的查询提供程序又向前走了一步!
下篇文章我会实现Select操作。
]]>英文原文是Matt Warren发表在MSDN Blogs的系列文章之一,英文渣渣,翻译不供参考,请直接看原文。
在上篇文章中,我们已经打好了基础,定义了可重用的IQueryable和IQueryProvider,它们分别是Query<T>类和QueryProvider类,现在我们来构建一个真正有用的提供程序。我之前说过,一个查询提供程序所做的事就是执行一些“代码”,这些“代码”使用表达式树而不是真正的IL语言来定义。当然,这并不一定是传统意义上的执行。比如说,LINQ to SQL就是将查询表达式翻译为SQL然后送到服务器中去执行的。
我下面给出的示例与LINQ to SQL有点类似,都是针对一个DAO provider对查询进行翻译和执行。但是,我要做个免责声明,在任何意义上,我给出的示例都不是一个完整的提供程序。我只会翻译Where操作,并且只支持在谓词中使用一个字段引用和一些简单的运算符,除此之外没有任何复杂的东西。以后我可能会扩展这个提供程序,但现在仅用于说明的目的。所以不要以为复制粘贴就能得到高质量的代码。
这个提供程序主要做两件事:
QueryTranslator简单地访问查询表达式树中的每个节点,然后用StringBuilder将支持的操作转换成文本。为了代码的清晰,我们假设有一个叫ExpressionVisitor的类,它定义了访问表达式节点的基本模式(我会在文章的结尾附上这个类的代码的,现在暂且将就一下)。
1 | internal class QueryTranslator : ExpressionVisitor { |
你看,这里虽然没有多少东西,但是也相当复杂。我所支持的表达式树充其量就是具有两个参数的方法调用节点,这两个参数一个是调用源(argument 0),一个是谓词(argument 1)。看上面的VisitMethodCall方法,我显式处理了Queryable.Where方法,生成SELECT * FROM (,递归访问调用源然后拼接上) AS T WHERE ,最后再访问谓词,这样就可以在调用源中以嵌套子查询的方式支持其他查询操作。我没有处理其他的查询操作,但是通过这种方式,也能优雅地处理多个连续的Where方法调用。表的别名可以随便起(我用了“T”),因为我没有生成任何对别名的引用。一个完备的提供程序当然会提供这个。
这里有个叫StripQuotes的帮助方法,它的作用是去除所给参数的所有ExpressionType.Quotes节点,以取得原本的lambda表达式。
VisitUnary和VisitBinary方法比较直截了当,它们简单地插入所支持的一元或二元操作所对应的正确的SQL文本。有趣的是VisitConstant方法,在这个示例中,只有处于表达式树的根处的IQueryable对象才与实际的数据表有关联。我假设Query<T>类的实例的constant节点代表了递归到最后的实际的数据表,于是我将SELECT * FROM和表名拼接了上去,这里的表名只是简单地以ElementType的返回类型的名称来充当。其他类型的constant节点只是被处理为实际的常量,这些常量将被作为直接量拼接到SQL命令中,并没有任何防止SQL注入攻击的手段,而这是一个真正的提供程序必须做的事。
最后,VisitMemberAccess方法假定所有对字段或属性的访问都代表着SQL命令中对数据列的引用,假定字段名或属性名就是数据库中的列名。并没有任何的检查来确保这个一致性。给定一个类Customers,它的字段与Northwind示例数据库中的列完全匹配,查询翻译器生成SQL的方式如下。
对于查询:
1 | Query<Customers> customers = ...; |
生成如下SQL:
1 | SELECT * FROM (SELECT * FROM Customers) AS T WHERE (City = ‘London’) |
对象读取器的作用是将SQL查询返回的结果转换为对象。我写了一个简单的类,它的构造方法以DbDataReader为参数,具有类型参数T,还实现了IEnumerable<T>接口。这里面也没有什么花哨的东西,只是使用反射来为类的字段赋值罢了。字段的名字必须与DbDataReader中的列名匹配,并且字段的类型也要与之兼容。
1 | internal class ObjectReader<T> : IEnumerable<T>, IEnumerable where T : class, new() { |
ObjectReader类为从DbDataReader中读取出来的每一行数据创建一个T类型的对象,使用反射APIFieldInfo.SetValue来给对象中的每一个字段赋值。ObjectReader对象被创建的时候会实例化一个内部类Enumerator的对象,GetEnumerator方法被调用的时候会返回这个枚举器。因为DbDataReader不能重置和再次运行,所以这个枚举器也只能被使用一次,第二次调用GetEnumerator会抛出一个异常。
ObjectReader对字段并没有严格的排序,这是因为QueryTranslator使用SELECT *来拼接SQL,这是不可避免的,因为程序没有办法知道结果中的列的顺序。注意,一般来说不建议在生产代码中使用SELECT *,这里只是出于说明的目的。为了支持返回结果中不同的列顺序,准确的序列会在运行时从DbDataReader中读取到第一条数据时生成。InitFieldLookup函数会创建一个从列名到列序数的一个映射,然后构建一个从对象的字段到列序数的查找表fieldLookup。
有了上面的两个类和上篇文章中定义的类,现在已经可以很容易就把它们结合起来,写出一个真正的IQueryableLINQ提供程序。
1 | public class DbQueryProvider : QueryProvider { |
GetQueryText方法使用QueryTranslator来产生SQL命令,Execute方法使用QueryTranslator和ObjectReader来创建DbCommand对象、执行命令、返回IEnumerable类型的结果。
现在,我们已经有了一个提供程序,让我们来写个demo试试看。仿照LINQ to SQL的模式,我定义了一个对应于Customers表的类,一个保存了查询对象(根查询)的“Context”,和一个使用了它们的小程序。
1 | public class Customers { |
运行这个程序,会得到下面的输出(注意必须将上面的数据库连接串替换成你自己的):
1 | Query: |
Excellent,正是我们想要的,计划实现了,心里有点小激动呢。
就是你了皮卡丘,这就是一个LINQIQueryable提供程序,起码算是一个粗糙的原型。当然你还可以在里面做更多的事情,处理各种各样的情况。
别急,还有更精彩的。查看Part III。
吊了这么久胃口,我感觉向我要ExpressionVisitor类的代码的人可能会比问我如何构建查询提供程序的人还要多。System.Linq.Expressions里面就有一个ExpressionVisitor类,但是它是internal的,所以尽管你很想直接用,但是并不能。如果你强烈要求的话说不定我们会在下个版本里面把它改成public。
我写的这个ExpressionVisitor使用了经典访问者模式。这里只有一个访问者类,用来将Visit方法的调用分派到与不同节点类型匹配的特定的VisitXXX方法。注意每个节点类型都会对应一个方法,比如二元运算节点就会被分派到VisitBinary方法。节点本身并不直接参与访问操作,它们仅仅被视为数据。这是因为访问者的数量是不限的,你也可以写一个自己的访问者类,这样可以让访问语义集中在访问者类中,避免其耦合到不同的节点类中去。对节点XXX的默认访问行为定义在基类的VisitXXX方法中。
每个VisitXXX方法都会返回一个节点。表达式树是不可变的,想改变表达式树就必须构建一颗全新的树。默认的VisitXXX方法在子树发生了变化的时候会创建一个新的节点,否则返回原来的节点。这样,如果你在树的深处(通过创建一个新节点)改变了一个节点,剩余的整棵树都会自动重新创建。
下面是源码,Enjoy。
1 | public abstract class ExpressionVisitor { |
英文原文是Matt Warren发表在MSDN Blogs的系列文章之一,英文渣渣,翻译不供参考,请直接看原文。
这段时间我一直打算写一个系列的文章来介绍如何使用IQueryable构建LINQ提供程序。也一直有人通过微软内部邮件、论坛提问或者直接给我发邮件的方式来给我这方面的建议。当然,通常我都会回复“我正在做一个详尽的Sample来给你们展示这一切”,告诉他们很快所有内容都会发布。但是,相比仅仅发布一个完整的Sample,我觉得一步一步循序渐进地阐述才是一个明智的选择,这样我才能深挖里面的所有细节,而不是仅仅把东西扔给你们,让你们自生自灭。
我要说的第一件事是,在Beta 2版本里面,IQueryable不再只是一个接口,它被分成了两个:IQueryable和IQueryProvider。在实现这两个接口之前,我们先过一遍它们的内容。
使用Visual Studio的“go to definition”功能,你可以看到下面的代码
1 | public interface IQueryable : IEnumerable { |
当然,IQueryable现在已经没什么好看的,有趣的内容都被放到了新接口IQueryProvider那里。如你所见,IQueryable只有三个只读的属性。第一个属性返回元素的类型(或者IQueryable<T>里面的T)。注意,所有实现IQueryable的类都必须同时实现IQueryable<T>,反之亦然。泛型的IQueryable<T>是在方法签名里面使用得最频繁的。非泛型的IQueryable的存在主要是为了提供一个弱类型的入口,该入口主要应用在动态构建query的场景之中。
第二个属性返回这个IQueryable对象对应的Expression,这正是IQueryable的精髓所在。在IQueryable封装之下的真正的“查询”是一个表达式树,它将query对象表示为一个由LINQ查询方法/操作符组成的树形结构,这是构建一个LINQ提供程序必须理解的原理。仔细看你就会发现,整个IQueryable的结构体系(包括LING标准查询操作符的System.Linq.Queryable版本)只是自动为你创建了表达式树。当你使用Queryable.Where方法来过滤IQueryable中的数据的时候,它只是简单地创建了一个新的IQueryable对象,并在原有的表达式树顶上创建一个MethodCallExpression类型的节点,该节点表示一次Queryable.Where方法的调用。不信?你自己试试看就知道了。
现在就只剩最后一个属性,这个属性返回新接口IQueryProvider的实例。我们把所有构造IQueryable实例和执行查询的方法都分离到了这个新接口中,这样能更加清晰地表示出查询提供程序的概念。
1 | public interface IQueryProvider { |
看到这个IQueryProvider接口,你可能会疑惑为什么有这么多方法。实际上这里只有两个操作,CreateQuery和Execute,只不过每个操作都有一个泛型的版本和一个非泛型的版本。当你直接在代码里面写查询的时候,一般都是调用泛型的版本。使用泛型的版本可以避免使用反射创建实例,因此性能更佳。
正如其名,CreateQuery方法的作用是根据指定的表达式树创建一个新的IQueryable对象。当这个方法被调用时,你的提供程序应该返回一个IQueryable对象,这个对象被枚举的时候会调用你的提供程序来处理这个指定的表达式。Queryable的标准查询操作符就是调用这个方法来创建与你的提供程序保持关联的IQueryable对象。注意,调用者可能会传给你的这个API一个任意的表达式树,对你的提供程序而言,传入的表达式树甚至可能是非法的,但是可以保证的是它一定会符合IQueryable对象的类型要求。IQueryable对象包含了一个表达式,这个表达式是一个代码的片段,当它转换为真正的代码并且执行的时候就会重新构造一个等价的IQueryable对象。
Execute方法是你的提供程序真正执行查询表达式的入口。应提供一个明确的Execute方法而不要仅仅依赖于IEnumerable.GetEnumerator(),以支持那些不必返回一个序列的查询。比如,这个查询“myquery.Count()”返回一个整数,该查询的表达式树是对返回整数的Count方法的调用。Queryable.Count方法(以及其他类似的聚合方法)就是调用Execute来“立即”执行查询。
讲到这里,是不是看起来就没那么难了?你自己也可以很轻松地实现所有的方法对吧?但是何必这么麻烦呢,我在下面就会给出代码。当然Execute方法除外,这个我会在以后的文章中给出。
让我们先从IQueryable开始。因为这个接口已经被划分成了两个,所以现在可以只用实现一次IQueryable,然后把它用在任意一个IQueryProvider中。下面给出一个Query<T>类,它实现了IQueryable<T>以及其他一系列的接口。
1 | public class Query<T> : IQueryable<T>, IQueryable, IEnumerable<T>, IEnumerable, IOrderedQueryable<T>, IOrderedQueryable { |
你看,IQueryable的实现十分简单。这个小对象所做的事情仅仅是保持一颗表达式树和一个查询提供者的实例,而查询提供者才是真正有趣的地方。
好了,下面把Query<T>类中引用到的QueryProvider给出,它是一个抽象类。一个真正的提供程序只需继承这个类,实现里面的Execute抽象方法。
1 | public abstract class QueryProvider : IQueryProvider { |
这个抽象类实现了IQueryProvider接口。两个CreateQuery方法负责创建Query<T>的实例,两个Execute方法将执行操作交给了尚未实现的Execute抽象方法。
我认为你可以把这个当成构建LINQ IQueryable提供程序的样板代码。真正的执行操作放在Execute方法中,在这里,你的提供程序可以通过检查表达式树来理解查询的具体含义,而这就是我接下来要讲的内容。
更新:
我好像忘了定义在代码里面用到的helper类,下面给出。
1 | internal static class TypeSystem { |
好吧,我知道这个helper类的代码比其他地方的都多。
Sigh.